 全部案例
全部案例
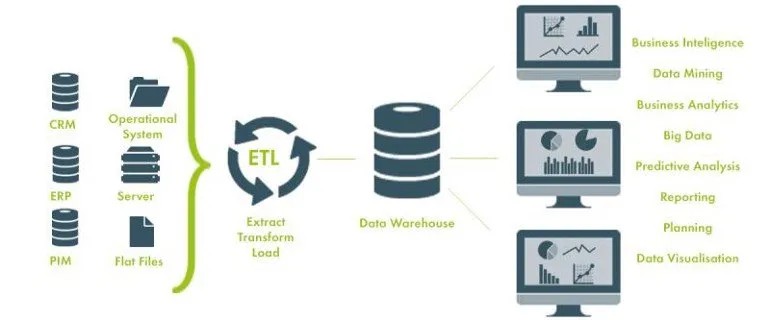 90年代起,国内建立了很多的信息管理系统,比如中小制造业工厂的进销存,大厂的MES,ERP等。这些初期的信息系统对关系型数据库的需求猛增,随之做数据库开发的朋友也越来越多。
初期建立的这些系统,都服务于特定的部门,比如销售部门的订单系统,生产部门的仓库管理,还有生产线上的 MES。虽然很快解决了特定部门的用数需求,提高了管理效率,但针对这么多小系统,在全公司范围内,能有一个统一视角来走查数据,是不够高效的。
甚至绝大多数公司,各个部门的数据接口是断层的。也就是,统计口径不唯一,给整个公司的运营层面带来的效率提升并不高。
因此,公司层面为了能够满足数据一致性,满足业务多维度的考察分析,开始了数据仓库的铺设。
早期的架构基本上都按照上面这张图设计。从公司早期建立的信息系统抽取数据,经过一系列数据格式的转变或合并,汇聚到一个数据库里面。各个部分需要数据时,从这个大集中的数据仓库中来取数。
熟悉数据仓库的朋友,都知道上图是 Kimball 理论的实现。Kimball 理论之所以这么流行,我想和他这种概念清晰好懂是分不开的。整个数据仓库项目,被清楚地划分为了四部分,源系统,ETL, 数据仓库,可视化分析。
注:这里涉及数据建模,通常会有 Kimball 与 Inmon 的对比。两者的优劣与选择,同样留到以后讲。
90年代起,国内建立了很多的信息管理系统,比如中小制造业工厂的进销存,大厂的MES,ERP等。这些初期的信息系统对关系型数据库的需求猛增,随之做数据库开发的朋友也越来越多。
初期建立的这些系统,都服务于特定的部门,比如销售部门的订单系统,生产部门的仓库管理,还有生产线上的 MES。虽然很快解决了特定部门的用数需求,提高了管理效率,但针对这么多小系统,在全公司范围内,能有一个统一视角来走查数据,是不够高效的。
甚至绝大多数公司,各个部门的数据接口是断层的。也就是,统计口径不唯一,给整个公司的运营层面带来的效率提升并不高。
因此,公司层面为了能够满足数据一致性,满足业务多维度的考察分析,开始了数据仓库的铺设。
早期的架构基本上都按照上面这张图设计。从公司早期建立的信息系统抽取数据,经过一系列数据格式的转变或合并,汇聚到一个数据库里面。各个部分需要数据时,从这个大集中的数据仓库中来取数。
熟悉数据仓库的朋友,都知道上图是 Kimball 理论的实现。Kimball 理论之所以这么流行,我想和他这种概念清晰好懂是分不开的。整个数据仓库项目,被清楚地划分为了四部分,源系统,ETL, 数据仓库,可视化分析。
注:这里涉及数据建模,通常会有 Kimball 与 Inmon 的对比。两者的优劣与选择,同样留到以后讲。
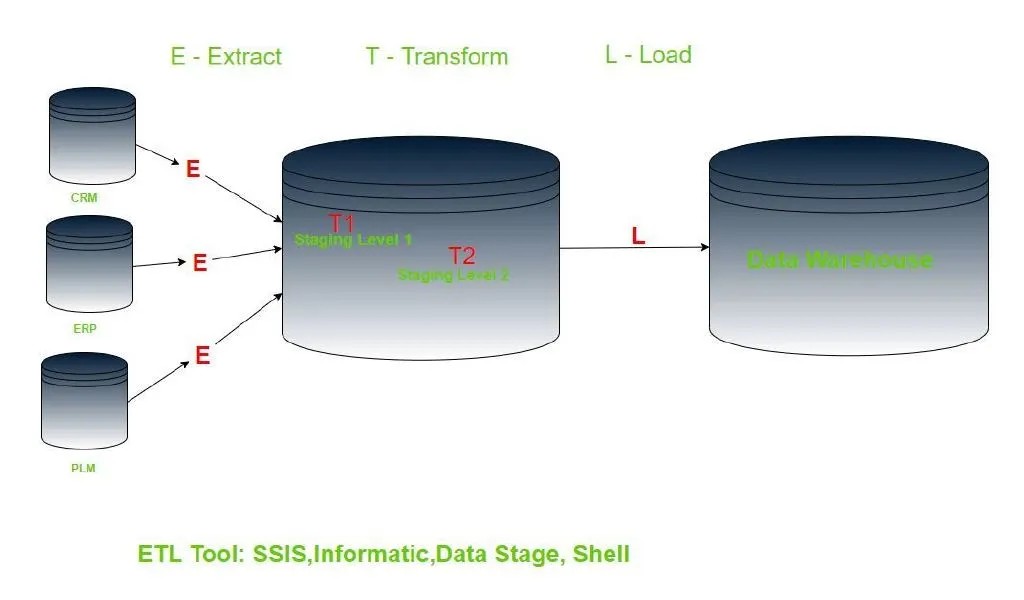 这是张经典的传统 ETL 架构图。将数据从各源业务系统区抽到缓冲数据存储库,经过存储过程做数据转换和聚合,再加载到数据仓库。每个项目都会有些细微的设计,但归总起来,就是这个流程。
当业务系统翻了十倍,甚至百倍的数据量之后,上面的 ETL 工具变得非常无力。因此引入了大数据技术。以 Hadoop 为基础的分布式存储和计算,使得分析和存储大量数据,变得高效。
这是张经典的传统 ETL 架构图。将数据从各源业务系统区抽到缓冲数据存储库,经过存储过程做数据转换和聚合,再加载到数据仓库。每个项目都会有些细微的设计,但归总起来,就是这个流程。
当业务系统翻了十倍,甚至百倍的数据量之后,上面的 ETL 工具变得非常无力。因此引入了大数据技术。以 Hadoop 为基础的分布式存储和计算,使得分析和存储大量数据,变得高效。
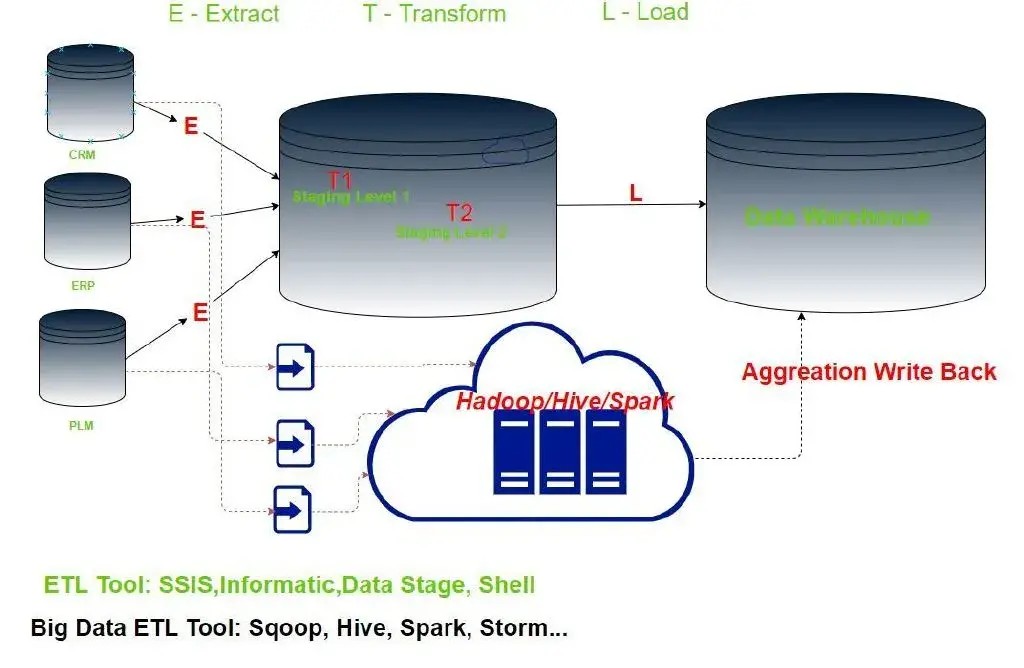 此时的ETL工具,围绕着 MapReduce 做了很多改造,比如 Sqoop, Hive, Spark 等等。借助这些工具,最终完成聚合计算,并同步到数据仓库中。
此时的ETL工具,围绕着 MapReduce 做了很多改造,比如 Sqoop, Hive, Spark 等等。借助这些工具,最终完成聚合计算,并同步到数据仓库中。
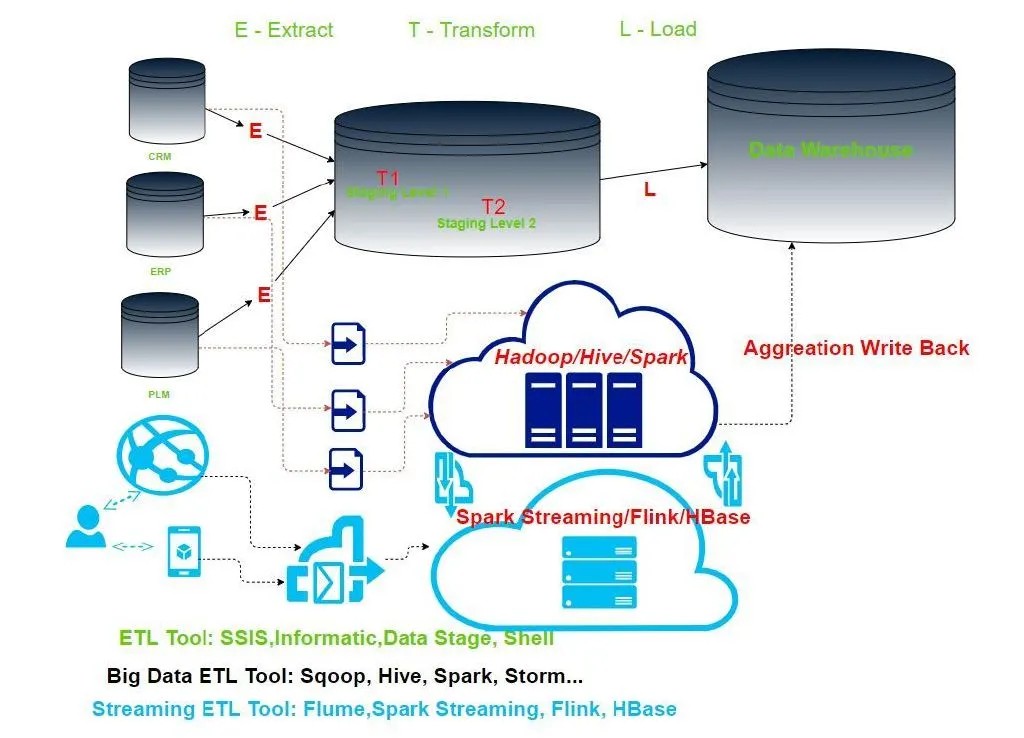 此时的实时数据处理,不再沿用传统的批次策略,而是每一次点击,滑动,切换都要实时地被计算框架给捕获,并给出反馈,或者推荐,或者聚合计算。类似 Flume, Kafka,Spark Streaming, Flink, HBase 的实时处理引擎,既要承接成百上千万的用户行为数据,还要与行为模型做交互,实时给出计算结果。
所以 ETL 是 SQL 人重启辉煌之光的必经之路。
此时的实时数据处理,不再沿用传统的批次策略,而是每一次点击,滑动,切换都要实时地被计算框架给捕获,并给出反馈,或者推荐,或者聚合计算。类似 Flume, Kafka,Spark Streaming, Flink, HBase 的实时处理引擎,既要承接成百上千万的用户行为数据,还要与行为模型做交互,实时给出计算结果。
所以 ETL 是 SQL 人重启辉煌之光的必经之路。


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号