 全部案例
全部案例
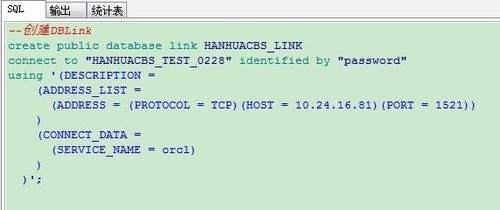 如果Oracle一统天下,ETL就失去了意义,数据湖这个概念都不好意思提出来,因为没有意义。Oracle DBLINK就是简约而不简单的代名词,其生命力之强大令人发指,这是真正的技术集约化提升生产力。
即使到今天,我们的数据集市还留有源端系统的DBLINK后门,因为数据获取快捷实时,可以小而美的解决一些问题,当然源端业务数据库变成了BC库或者容灾库,虽然DBLINK备受耦合的骂名。
那个时候还没有建模的概念,但公司的报表、取数前辈已经基于实践沉淀出了很多汇总表和宽表,当你的公司业务不够复杂、数据量还不够大的时候,谈关系建模,维度建模都没什么意义,前辈创建的中间表就是一切,只要能快速的满足报表取数需求。
有了DBLINK和宽表,那么Oracle时代最强大的Pass是什么呢?
当然是PL/SQL Developer这个集成开发工具,其是专门开发面向Oracle数据库的应用,PL/SQL叫做过程化SQL语言(Procedural Language/SQL),是Oracle数据库对SQL语句的扩展,其在普通SQL语句的使用上增加了编程语言的特点,比如把数据操作和查询语句组织在PL/SQL代码的过程性单元中,通过逻辑判断、循环等操作实现复杂的功能或者计算。
如果Oracle一统天下,ETL就失去了意义,数据湖这个概念都不好意思提出来,因为没有意义。Oracle DBLINK就是简约而不简单的代名词,其生命力之强大令人发指,这是真正的技术集约化提升生产力。
即使到今天,我们的数据集市还留有源端系统的DBLINK后门,因为数据获取快捷实时,可以小而美的解决一些问题,当然源端业务数据库变成了BC库或者容灾库,虽然DBLINK备受耦合的骂名。
那个时候还没有建模的概念,但公司的报表、取数前辈已经基于实践沉淀出了很多汇总表和宽表,当你的公司业务不够复杂、数据量还不够大的时候,谈关系建模,维度建模都没什么意义,前辈创建的中间表就是一切,只要能快速的满足报表取数需求。
有了DBLINK和宽表,那么Oracle时代最强大的Pass是什么呢?
当然是PL/SQL Developer这个集成开发工具,其是专门开发面向Oracle数据库的应用,PL/SQL叫做过程化SQL语言(Procedural Language/SQL),是Oracle数据库对SQL语句的扩展,其在普通SQL语句的使用上增加了编程语言的特点,比如把数据操作和查询语句组织在PL/SQL代码的过程性单元中,通过逻辑判断、循环等操作实现复杂的功能或者计算。
 直到今天我们的大数据开发管理平台的很多设计理念都是直接借鉴 PL/SQL Developer。每次我都会对DACP的产品经理说,学习下 PL/SQL Developer的功能和体验,直接抄也行啊,大多也源于我对PL/SQL Developer的感情吧,不过它的确太优秀了。
这里贴一段以前做ALL表时的SQL代码,各种decode,我的代码生涯至少做过3000个类似的脚本。
直到今天我们的大数据开发管理平台的很多设计理念都是直接借鉴 PL/SQL Developer。每次我都会对DACP的产品经理说,学习下 PL/SQL Developer的功能和体验,直接抄也行啊,大多也源于我对PL/SQL Developer的感情吧,不过它的确太优秀了。
这里贴一段以前做ALL表时的SQL代码,各种decode,我的代码生涯至少做过3000个类似的脚本。
 再贴一段以前的存储过程代码,也很方便。
再贴一段以前的存储过程代码,也很方便。
 即使是现在,只要企业的源端数据库没有去O,Oracle作为数据集市来讲也是非常合适的,况且Oracle的一体机一点不含糊,应对一般的报表取数绰绰有余。
即使是现在,只要企业的源端数据库没有去O,Oracle作为数据集市来讲也是非常合适的,况且Oracle的一体机一点不含糊,应对一般的报表取数绰绰有余。

昂贵而牛逼的P595
 以前Brio报表数据的刷新是定时的,定时在9点刷新,即使数据在6点生成好了也没用,有个合作伙伴的小伙子就把触发式的刷新功能做出来了,厉害得很,后来跳槽了,现在在腾讯做到很高的职位。
还有就是财务部门希望每月定时把一大批报表自动导成excel推送给他们,因为要的报表太多了,不希望登录到报表门户一张张点开处理,这个时候就要brio做批量生成excel的功能。
我以前在文章中说,BI近年来没多少长进,是指没有发生什么革命性的变化,诸如brio等早期的BI工具还有自身的特点,比如报表数据以bqy的文件方式存储,你可以随意下载和拷贝,不需要登录什么服务,在任何一台有brio客户端的电脑都能打开,然后做各种线下的拖拉钻取报表操作。
但是现在被敏捷式BI如FineBI和Tableau取代了。
以前Brio报表数据的刷新是定时的,定时在9点刷新,即使数据在6点生成好了也没用,有个合作伙伴的小伙子就把触发式的刷新功能做出来了,厉害得很,后来跳槽了,现在在腾讯做到很高的职位。
还有就是财务部门希望每月定时把一大批报表自动导成excel推送给他们,因为要的报表太多了,不希望登录到报表门户一张张点开处理,这个时候就要brio做批量生成excel的功能。
我以前在文章中说,BI近年来没多少长进,是指没有发生什么革命性的变化,诸如brio等早期的BI工具还有自身的特点,比如报表数据以bqy的文件方式存储,你可以随意下载和拷贝,不需要登录什么服务,在任何一台有brio客户端的电脑都能打开,然后做各种线下的拖拉钻取报表操作。
但是现在被敏捷式BI如FineBI和Tableau取代了。
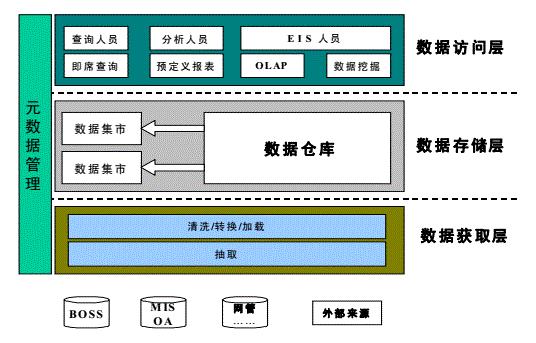 数据获取层:将BOSS、MIS等外部数据源的数据进行清洗、转换和加载到数据仓库,关于ETL也有路线之争,其实我们真正做的是ELT,复杂的转换全部是在库内完成的。而且我们的ETL还有一个后门,就是数据集市Oracle直接通过DBLINK获取源端数据,隐患还是挺大的。
数据存储层:实现对数据仓库中数据和元数据的集中管理,即DB2,并根据需要建立面向部门的数据集市(老的报表库退化为数据集市),数据集市和元数据这么早提出来也是非常有先见之明的,当然也只是提出而已,并没有完全落地。
数据访问层:通过多样化的前端展现工具,实现数据的分析,形成市场经营和决策工作所需要的业务信息和知识,采用的就是前面所说的Brio工具。
数据获取层:将BOSS、MIS等外部数据源的数据进行清洗、转换和加载到数据仓库,关于ETL也有路线之争,其实我们真正做的是ELT,复杂的转换全部是在库内完成的。而且我们的ETL还有一个后门,就是数据集市Oracle直接通过DBLINK获取源端数据,隐患还是挺大的。
数据存储层:实现对数据仓库中数据和元数据的集中管理,即DB2,并根据需要建立面向部门的数据集市(老的报表库退化为数据集市),数据集市和元数据这么早提出来也是非常有先见之明的,当然也只是提出而已,并没有完全落地。
数据访问层:通过多样化的前端展现工具,实现数据的分析,形成市场经营和决策工作所需要的业务信息和知识,采用的就是前面所说的Brio工具。
 关于模型设计自己没机会参与,因为刚进公司,啥都不懂,记得参加过几次项目例会(亚信是当时的集成商),印象最深的就是亚信北京研发的数据模型专家在那边讨论模型的设计方案,还有跟局方的争论,一些新的名词不停的跳出来,什么erwin、概念模型、逻辑模型、物理模型、ER图,PDM等等,自己一头雾水。
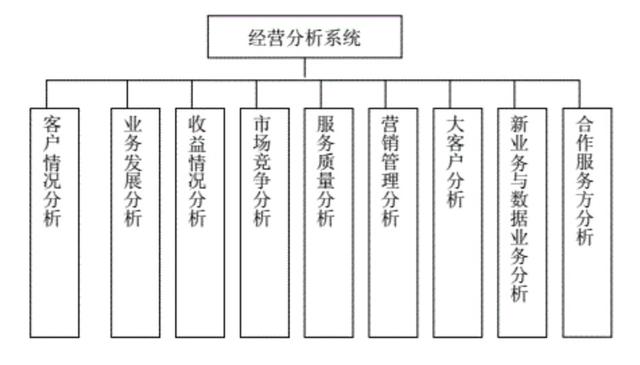
下图是中国移动业务的概念模型。
关于模型设计自己没机会参与,因为刚进公司,啥都不懂,记得参加过几次项目例会(亚信是当时的集成商),印象最深的就是亚信北京研发的数据模型专家在那边讨论模型的设计方案,还有跟局方的争论,一些新的名词不停的跳出来,什么erwin、概念模型、逻辑模型、物理模型、ER图,PDM等等,自己一头雾水。
下图是中国移动业务的概念模型。
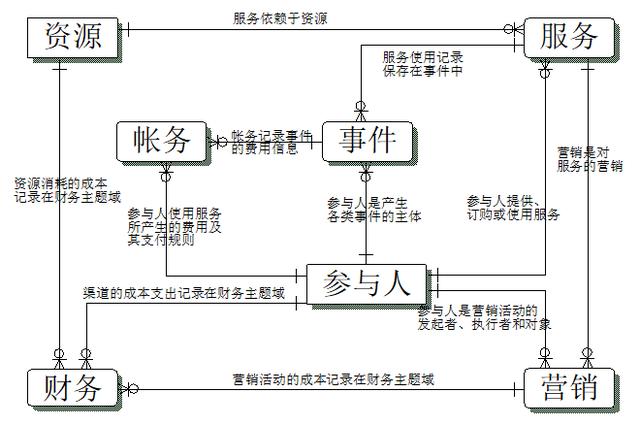 下图是其中的事件主题的逻辑模型。
下图是其中的事件主题的逻辑模型。
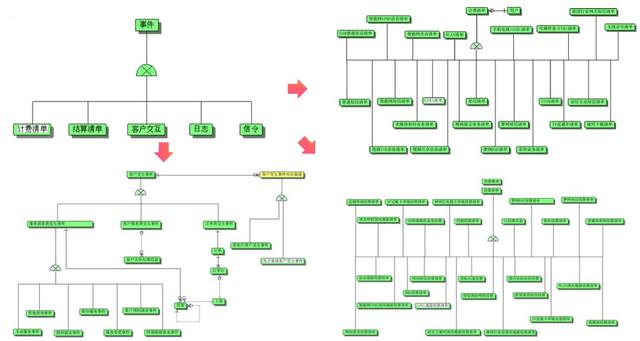 第一代数据仓库的建设持续了一年多,其实跟我没多大关系,只有使用上的一些体会,九大主题建设完成后最大的感受是可以用BI工具看报表了,但九大主题使用的人并不是很多。
现在很容易想明白原因,因为第一代数据仓库基本还是技术驱动,虽然经营分析系统规范有集团公司的顶层业务规划,但到了省公司业务人员参与度就低了,规范如何跟本地业务相结合一直是数据仓库的巨大挑战。
但无论如何,2005年是值得庆祝的一年,因为我们的数据仓库起航了,从0到1总是有很大的意义。
第一代数据仓库的建设持续了一年多,其实跟我没多大关系,只有使用上的一些体会,九大主题建设完成后最大的感受是可以用BI工具看报表了,但九大主题使用的人并不是很多。
现在很容易想明白原因,因为第一代数据仓库基本还是技术驱动,虽然经营分析系统规范有集团公司的顶层业务规划,但到了省公司业务人员参与度就低了,规范如何跟本地业务相结合一直是数据仓库的巨大挑战。
但无论如何,2005年是值得庆祝的一年,因为我们的数据仓库起航了,从0到1总是有很大的意义。
很显然在目前的信息时代,借助类似于FineDataLink的这些工具,可以让企业加速融入企业数据集成和分析的趋势。备受市场认可的软件其实有很多,选择时必须要结合实际的情况。一般的情况下,都建议选择市面上较主流的产品,比较容易达到好的效果,就是帆软的数据集成平台——FineDataLink。


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号