作者:finedatalink
发布时间:2023.8.15
阅读次数:538 次浏览
随着大数据时代的到来,处理海量数据的需求越来越迫切。而Spark作为一款开源的大数据处理框架,具备了很多优势。本文将探讨Spark计算引擎在大规模数据处理中的优势,并介绍其在不同领域的应用。
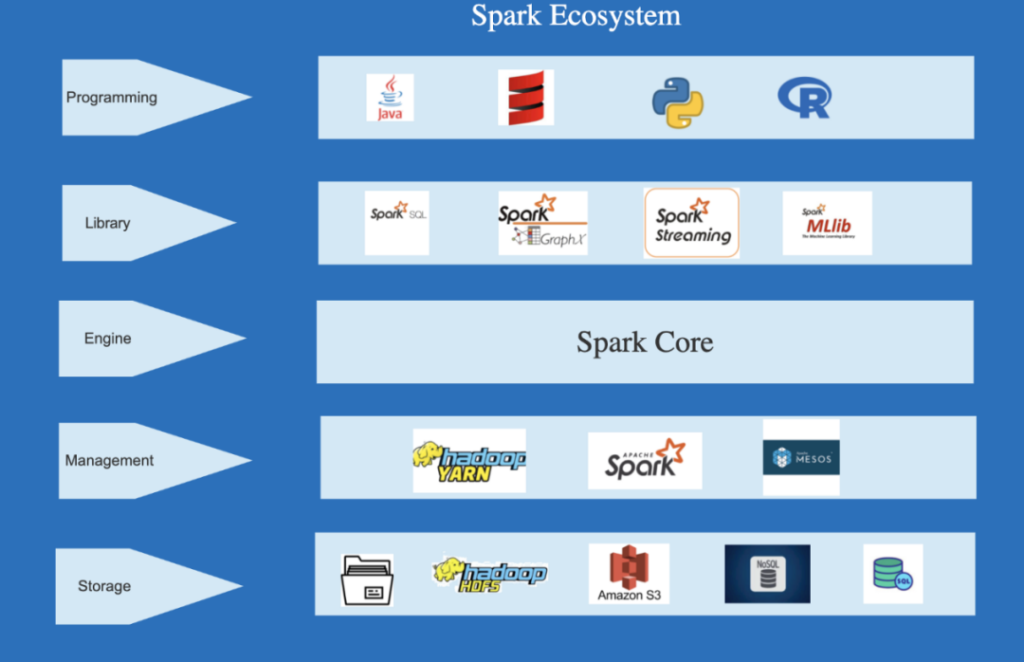
Spark采用了分布式计算模型,可以在集群中进行并行计算。其主要特点包括:
Spark使用内存计算技术,将数据保存在内存中,大大提高了计算速度。相比传统的批处理框架,如Hadoop的MapReduce,Spark可以达到数倍甚至数十倍的速度提升。
Spark支持多种数据处理模式,如批处理、流处理和交互式查询。而且,Spark可以与其他大数据生态系统集成,如Hive、HBase和Kafka等,提供更灵活的数据处理方案。
Spark提供了丰富的API,如Scala、Java、Python和R等,使得开发者可以使用自己熟悉的编程语言,方便快速地开发和调试应用程序。

大数据往往存在各种格式和结构的不一致性,Spark可用于数据处理和清洗,提供功能强大的数据转换和过滤操作,同时支持复杂的数据聚合和分析。
Spark提供了机器学习库MLlib,包括常见的机器学习算法和特征提取工具,可用于构建和训练模型,以及进行数据挖掘和预测分析。
Spark Streaming模块可以对实时数据进行分析和处理,支持与Kafka等流式处理引擎集成,可以实时监控和分析数据流,为用户提供及时的数据反馈和决策支持。
Spark GraphX是一个图计算库,可以支持大规模图数据的处理与分析,广泛应用于社交网络、网络分析等领域。
Spark作为一个分布式计算引擎,可以处理庞大的数据集。其弹性的集群管理和任务调度能力使得可以有效地并行处理大规模数据,提高数据处理的效率和可扩展性。
Spark基于内存计算和并行处理,具备快速的数据处理能力,对于大规模数据集可以显著提高计算效率。
Spark支持多种数据处理模式,适用于不同的业务需求,同时可以与其他大数据生态系统集成,提供灵活的数据处理解决方案。
Spark提供了多种编程语言的API,使得开发者可以使用自己熟悉的编程语言进行开发和调试,减少学习成本和开发周期。
Spark的生态系统庞大且活跃,包括了大量的第三方库和工具,为用户提供了丰富的功能和扩展性。
Spark计算引擎在大规模数据处理中具备了高性能、灵活性和丰富的API支持等优势。其在数据处理、机器学习、实时分析和图计算等领域应用广泛,为用户提供了完整的数据处理解决方案。随着大数据应用的不断发展,Spark的优势将更加凸显,对于大规模数据处理具有重要的意义。
在解决端到端异构数据问题的同时,FineDataLink追求更优的性能体验和更高的稳定性。FineDataLink内嵌了Spark计算引擎以增强数据同步过程中的处理和计算能力,结合ETL任务的异步/并发读写机制,保证了在数据同步和数据处理场景下的高性能表现。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 三分钟理解数据中台的质量监控与保障!下一篇: 精益求精:数据中台重塑数据清洗的未来


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号