作者:finedatalink
发布时间:2023.8.10
阅读次数:472 次浏览
在当今的数字化时代,数据成为了驱动企业决策和创新的重要资源。然而,随着数据规模不断增长,传统的数据处理方法已经无法满足对大规模数据的高效处理需求。幸运的是,Spark计算引擎的出现将大数据处理推向了一个新的高度。
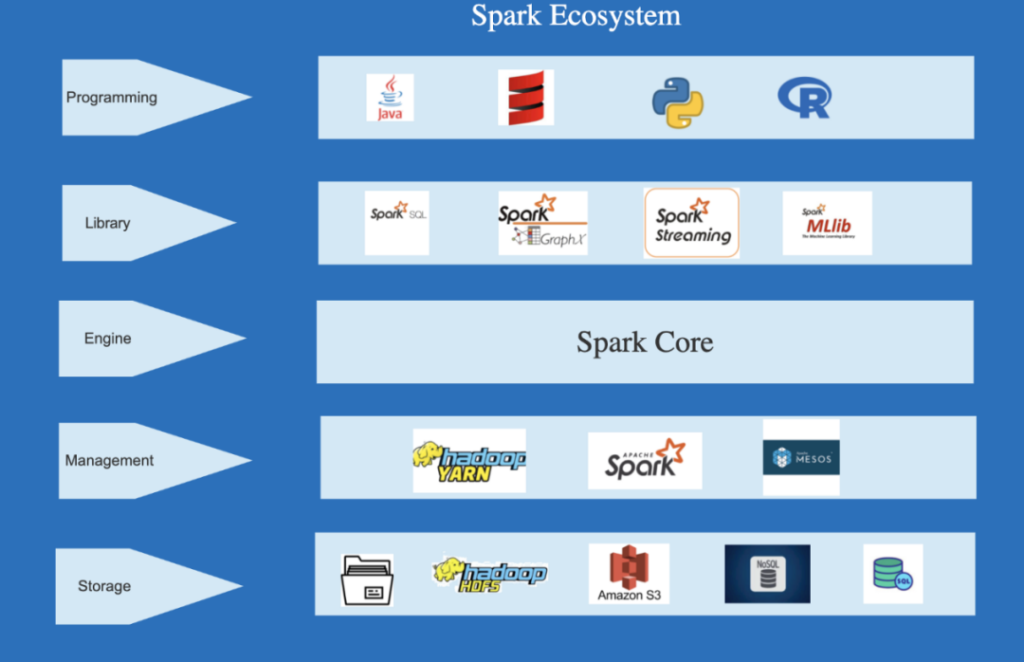
Spark计算引擎作为一种快速、可扩展的开源数据处理框架,针对大规模数据处理提供了许多优势。
首先,它通过将数据分布式存储在集群中的多个节点上,实现了并行计算。这意味着Spark能够同时处理多个数据片段,从而显著提高了数据处理的速度和效率。相比之下,传统的单机处理方法需要以串行方式处理数据,速度相对较慢。
其次,Spark计算引擎提供了丰富的数据处理功能和高级API,使得开发人员能够更加灵活地处理和操作大规模数据。无论是数据清洗、转换、聚合还是机器学习等任务,都可以在Spark上得到有效地支持。Spark还提供了多种开发语言的支持,如Java、Scala和Python等,使得开发人员能够使用自己熟悉的语言进行开发,提高了开发效率和灵活性。
此外,Spark还具备强大的内存计算能力。传统的数据处理方法通常需要将数据从磁盘加载到内存中进行处理,而Spark在内存中进行计算的能力极大地提高了数据处理的速度。内存计算不仅减少了磁盘读写的开销,还可以更快地响应用户的数据分析和查询需求,提高了数据处理的实时性。

由于大规模数据处理过程中可能发生各种错误和故障,如节点故障、网络中断等,因此可靠的容错机制对于大数据处理至关重要。Spark采用了弹性分布式数据集(ResilientDistributedDataset,简称RDD)和基于日志的容错技术,可以处理各种故障情况,并自动恢复,保证了数据处理的可靠性和稳定性。
最后,Spark计算引擎通过使用高级的优化技术,如基于内存的计算、查询优化和任务调度等,进一步提高了数据处理的质量。这些优化技术可以减少数据处理过程中的冗余计算和资源浪费,提高了数据处理的准确性和可靠性。Spark还支持分布式机器学习和图计算等高级应用,使得数据处理更加全面和丰富。
总的来说,Spark计算引擎在大数据处理中具有出色的性能和能力。它提供了高效的并行处理、丰富的数据处理功能、强大的内存计算能力、可靠的容错性和优化的数据处理质量。借助Spark,企业可以更好地利用大数据资源,提高决策效率、推动创新,并取得更大的业务成功。
在解决端到端异构数据问题的同时,FineDataLink追求更优的性能体验和更高的稳定性。
FineDataLink内嵌了Spark计算引擎以增强数据同步过程中的处理和计算能力,结合ETL任务的异步/并发读写机制,保证了在数据同步和数据处理场景下的高性能表现。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号