作者:finedatalink
发布时间:2023.8.7
阅读次数:407 次浏览
数据仓库ETL同步是数据仓库构建的核心过程,常用的数据仓库ETL同步策略分为两种:
① 全量同步
② 增量同步
接下来逐一介绍。
同时在文章《扫盲系列(4):数据仓库ETL流程和ETL工具推荐》中,我们介绍了数据仓库的数据仓库ETL流程和ETL工具推荐,感兴趣的可以进行查看。
数据仓库ETL工具推荐
全量同步适用于数据初始化装载和周期性数据更新的情况。
1. 数据初始化装载:由于没有任何数据基础,全量同步可以保证数据的完整性和一致性,直接将数据从源系统导出到目标系统中,无需做任何增量同步操作。
2. 周期性数据更新:因为业务和技术等原因,有时需要对数据进行全量更新,直接将新数据覆盖旧数据即可,这时候也需要使用全量同步的方式。
需要注意的是,在进行全量同步时,要确保源数据的正确性和完整性,同时也要确保数据仓库ETL过程的稳定性和安全性,避免数据丢失或数据混乱的情况发生。此外,由于全量同步需要处理大量数据,因此需要注意处理数据的效率和性能,避免对系统和业务造成过大的影响。
在实际应用中,通常需要结合增量同步等其他同步策略,采用不同的策略对不同类型的数据进行处理,以实现数据的全面同步和更新。
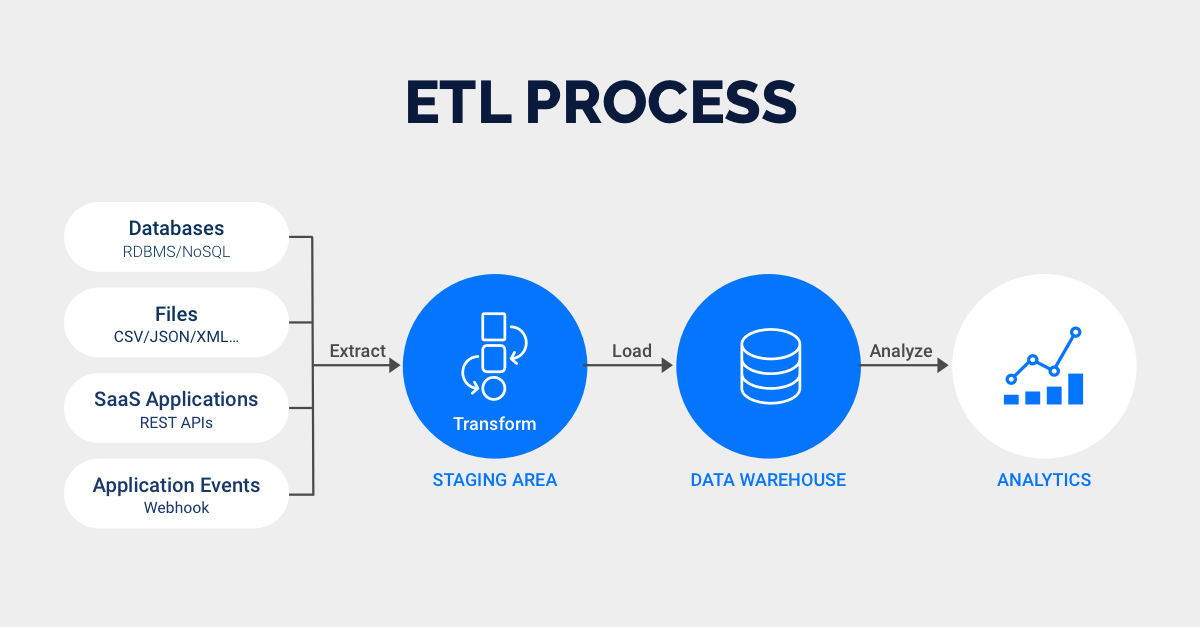
数据仓库ETL流程
增量同步适用于对已有数据进行更新和维护的情况。
1. 传统数据整合方案:通常采用merge方式,对源数据和目标数据进行比对,然后进行update和insert操作,但是,这种方式存在一定的安全隐患和效率问题。
2. 主流大数据平台:不支持update操作,通常采用全外连接+数据全量覆盖方式进行增量同步,即通过比较源数据和目标数据的差异来更新数据,同时避免了update操作可能带来的问题,并且可以降低数据仓库ETL的复杂度和开销。
需要注意的是,增量同步需要考虑到源数据的增量情况,需要数据同步变化,并及时更新目标系统中的数据,确保数据的一致性和准确性。同时,也需要注意增量同步的效率和稳定性,避免对系统和业务造成不必要的影响。与数据全量同步ETL相比,数据增量同步ETL可以用最少的资源提高数据同步效率。
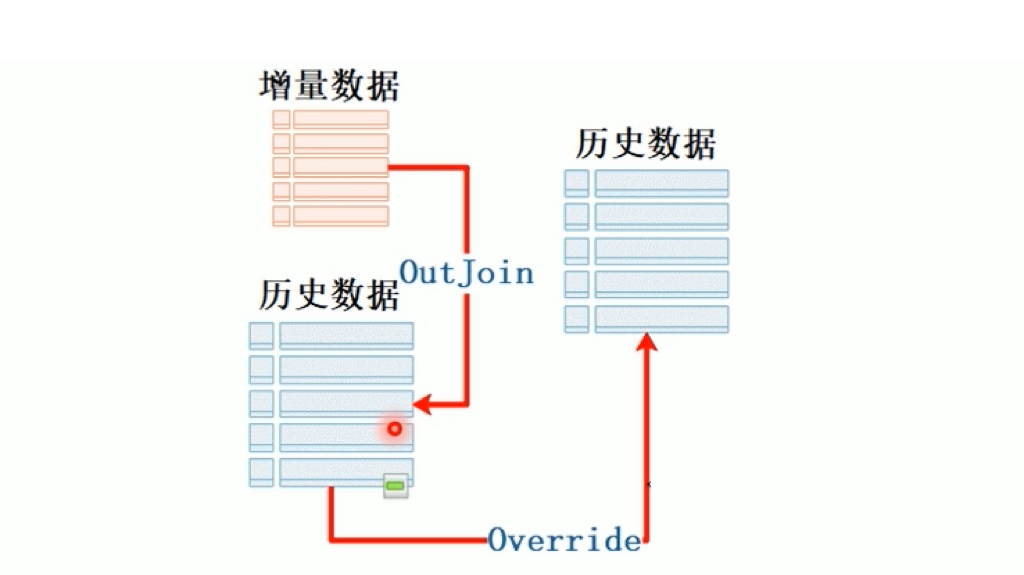
数据仓库ETL增量同步
数据仓库ETL同步可以借助工具来完成,例如前面的文章提过的ETL工具FineDataLink。拿增量同步来举例,FineDataLink的数据管道功能通过MySQL binlog、Oracle LogMiner、和SQL Sever的CDC等日志解析,来实现数据的增量获取。同时采用流式引擎,实时捕获源数据库的变化,在毫秒内更新到目标数据库,实现数据实时同步。

FineDataLink实现数据增量获取
FineDataLink是一款中国领先的低代码/高时效数据集成工具,能够帮助企业构建数据仓库,为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号