作者:finedatalink
发布时间:2023.7.25
阅读次数:639 次浏览
数据预处理和清洗是数据分析和挖掘的重要步骤,它们对于确保数据的准确性和可靠性至关重要。本文将介绍数据预处理和清洗的关键步骤和方法,帮助理解如何处理和清洗数据以确保数据的质量。
数据预处理是数据分析中最关键的步骤之一。在数据预处理过程中,我们会对原始数据进行清洗、转换、集成和规范化,以便更好地适应后续的数据分析工作。数据预处理的目标是消除数据中的错误、噪声和冗余,使数据能够被正确解释和使用。以下是数据预处理的主要步骤:
数据清洗是数据预处理的第一步,它包括去除重复数据、处理缺失值和异常值。
重复数据会对分析产生误导,因此需要将其删除。
缺失值通常需要进行填充,可以使用平均值、中位数或者回归等方法进行填充。
异常值则需要进行检测和处理,可以使用统计学方法、可视化方法等进行异常检测和处理。
数据转换包括对数据进行归一化、离散化、标准化等处理,以便更好地适应后续的数据分析模型。
归一化可以将数据的取值范围映射到[0,1]之间,
离散化可以将连续数据转化为离散的类别变量,
标准化可以将数据转化为具有零均值和单位方差的分布。
数据集成是将数据来源不同的数据集合并成一个一致的数据集。
在数据集成过程中,我们需要解决数据结构不一致、属性不匹配等问题,保证数据集整体的一致性和可用性。
数据规范化是将数据转换为适应特定数据分析算法的形式。
例如,某些算法对于二进制数据的处理效果更好,因此需要将非二进制数据转换为二进制数据。
数据规范化还包括数据压缩、特征选取和降维等操作,以减少数据的复杂性和冗余度。 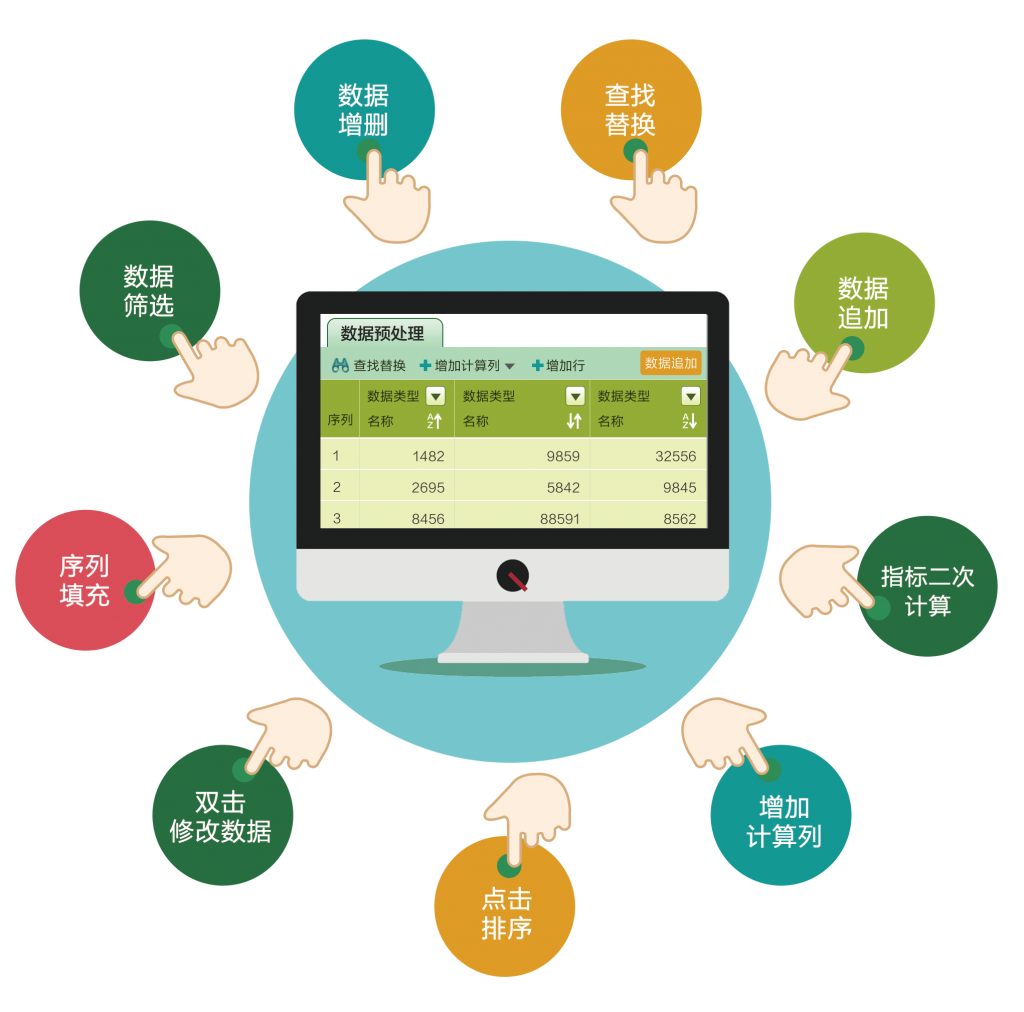
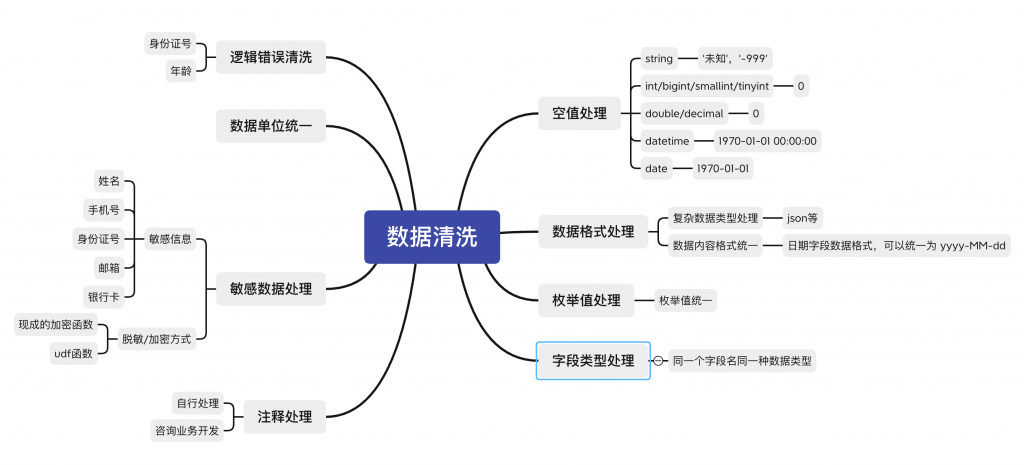
数据清洗是数据预处理过程中最为重要的环节之一。只有对数据进行有效的清洗,才能保证后续的分析工作的准确性和可靠性。数据清洗包括以下几个方面的工作:
重复数据会对分析结果产生误导,因此需要对数据中的重复项进行检测和删除。
数据中的缺失值会对分析结果产生较大的影响,因此需要对缺失值进行处理。一种常用的方法是使用均值、中位数或者回归等方法进行缺失值的填充。
异常值是指与其他观测值明显不同的数据点,可能会对分析产生误导。需要使用统计学方法、可视化方法等对异常值进行检测和处理。
在数据清洗过程中,还需要检查数据的一致性。例如,对于时间序列数据,需要检查数据的时间顺序和连续性。对于逻辑关系的数据,需要检查数据之间的逻辑关系是否符合实际情况。
数据格式转换是将数据转换为适合分析的格式。例如,将字符型数据转换为数值型,或者将数据从一种编码格式转换为另一种编码格式等。
数据预处理和清洗是确保数据准确性和可靠性的关键步骤。只有经过有效的数据预处理和清洗,才能保证后续的数据分析和决策的准确性。希望本文对读者理解数据预处理和清洗的重要性,并在实际工作中应用相关方法提供了帮助。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 一看就会!通过数据探索企业发展趋势下一篇: 三分钟了解数据源集成,让企业数据融合更高效


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号