作者:finedatalink
发布时间:2023.7.31
阅读次数:845 次浏览
数据仓库是现代企业中用于存储和分析大量数据的重要工具。在数据仓库中,增量加载和全量加载是两种常见的数据加载方法。它们分别用于增量更新和全量覆盖数据仓库中的数据。
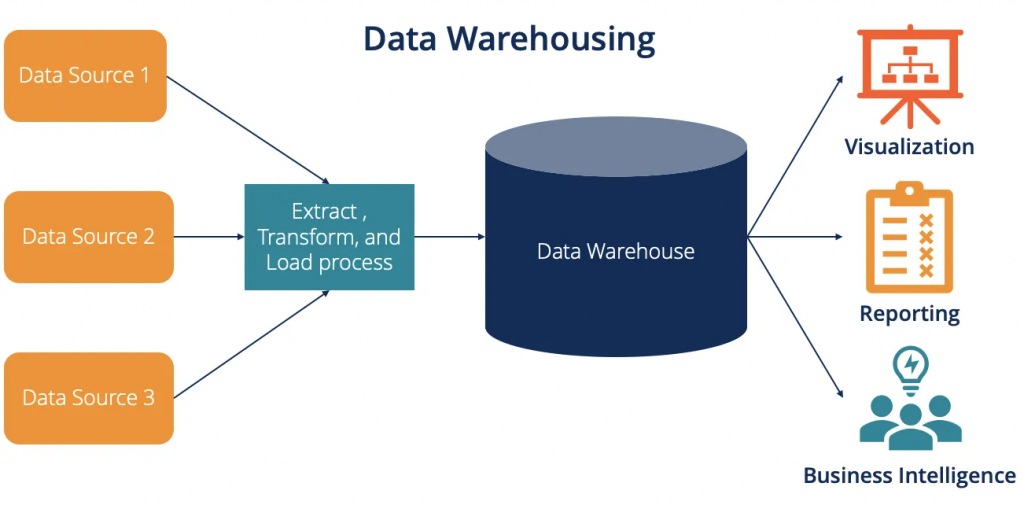
增量加载是指在已有数据的基础上,只加载并更新新增的或发生变化的数据。具体而言,它会对源数据进行比较,只将那些在源数据中新出现或发生变化的数据加载到数据仓库中。
增量加载具有高效性和实时性的特点,可以较快地将最新的数据同步到数据仓库中,方便用户及时获取最新的分析结果。增量加载常用于数据量庞大、高频更新的场景,如电商、金融等领域。
全量加载是指将所有源数据完整地加载到数据仓库中,并且覆盖之前的数据。全量加载通常用于初始化数据仓库或进行一次性的大规模数据同步。
全量加载能够确保数据的完整性和一致性,适用于需要全局数据分析和离线处理的场景,如市场调研、历史数据分析等。

增量加载适用于数据源经常发生变化的场景,如电商平台的订单数据、金融机构的交易数据等。通过增量加载,用户可以实时地获取最新的订单信息或交易数据,提高业务决策的准确性和时效性。
而全量加载一般适用于需要对整个数据集进行分析的场景,如统计一段时间内的销售数据、用户行为数据等。通过全量加载,用户可以获得完整的数据集,进行全面的分析和挖掘。
综上所述,数据仓库中的增量加载和全量加载是两种常见的数据加载方法。它们分别用于增量更新和全量覆盖数据仓库中的数据,并在不同的应用场景下发挥作用。
增量加载适用于数据量庞大、高频更新的场景,具有高效和实时的特点;
而全量加载适用于需要全局数据分析和离线处理的场景,保证数据的完整性和一致性。
通过合理选择和应用这两种数据加载方法,企业可以更好地利用数据仓库进行业务决策和数据分析。
FineDataLink是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业快速构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。同时,帆软FDL也支持开放API和服务接口,可以与其他数据工具和系统进行整合和拓展。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 数据仓库维护与性能优化技巧下一篇: 速看!元数据管理居然可以这么学!


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号