作者:finedatalink
发布时间:2023.7.25
阅读次数:332 次浏览
在当今信息爆炸的时代,各种类型的数据增长迅猛,如何高效地存储、管理和查询数据成为了极其重要的问题。设计合适的数据架构和数据模型可以极大地提升数据集成和查询效率,从而提升用户的数据体验。本文将从以下几个方面介绍如何设计合适的数据架构和数据模型,以支持数据集成和查询效率。
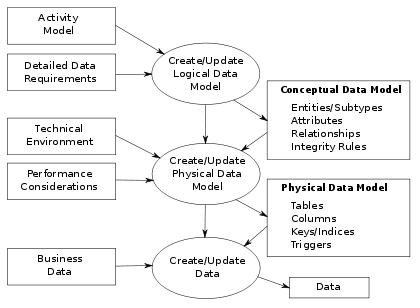
合理划分数据层级是设计高效数据架构的关键。根据业务需求和数据的逻辑关系,将数据划分为不同的层级。常见的数据层级包括原始数据层、清洗数据层、集成数据层、计算数据层和应用数据层。
原始数据层负责存储原始数据,
清洗数据层负责对原始数据进行清洗和预处理,
集成数据层负责将不同来源的数据进行整合,
计算数据层负责进行数据运算和统计分析,
应用数据层负责为应用程序提供数据支持。
通过合理划分数据层级,可以降低数据冗余度,提高数据查询效率。
选择合适的数据模型对于数据集成和查询效率至关重要。常见的数据模型包括关系型数据模型、面向对象数据模型和文档数据模型等。
关系型数据模型适用于结构化数据,具有较强的数据一致性和一对一关系;
面向对象数据模型适用于面向对象的应用场景,具有较强的数据封装性和多对多关系;
文档数据模型适用于非结构化数据,具有较好的扩展性和灵活性。
选择合适的数据模型可以提高数据的组织性和查询效率。
合理使用索引可以大幅度提升数据查询效率。索引是根据数据特定字段进行排序的数据结构,可以加快数据查询的速度。
在设计数据架构和数据模型时,需要根据业务需求和查询场景合理选择索引字段,并针对索引字段进行优化,如使用合适的数据类型、添加合理的索引选项等。此外,需要定期对索引进行维护和优化,如删除不需要的索引、重建索引等,以保持索引的高效性。
使用缓存技术可以进一步提升数据查询效率。缓存是将数据存储在高速访问介质中,以加速数据读取和响应速度的技术。通过合理使用缓存技术,可以缓解数据库的负载压力,并提高数据的访问效率。
常见的缓存技术包括内存缓存、分布式缓存和页面缓存等。
根据实际需求选择合适的缓存技术,并合理设置缓存策略,可以优化数据查询体验和系统性能。
综上所述,设计合适的数据架构和数据模型对于支持数据集成和查询效率至关重要。通过合理划分数据层级、选择合适的数据模型、使用索引和缓存技术等手段,可以提高数据的组织性和查询效率,优化用户的数据体验。在设计数据架构和数据模型时,需要根据具体业务需求和查询场景进行综合考量,并不断优化和调整,以适应不断变化的数据环境和用户需求。
FineDataLink 是一款低代码/高时效的ETL数据集成平台,面向用户大数据场景下,满足实时和离线数据采集、集成、管理的诉求,提供快速连接、高时效融合各种数据、灵活进行ETL数据开发的能力,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 三分钟学会选择算法和模型结构!下一篇: 居然可以这样!通过数据版本确保数据完整性和可靠性


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号