作者:finedatalink
发布时间:2023.8.25
阅读次数:518 次浏览
随着数据量的不断增长,企业面临着如何高效地存储和处理海量数据的挑战。在数仓搭建过程中,如何平衡数据存储成本和数据处理效率成为了一个重要的问题。本文将探讨在数仓搭建中的平衡之道,旨在帮助企业合理规划数据存储和处理策略,提高数据仓库的性能和效率。
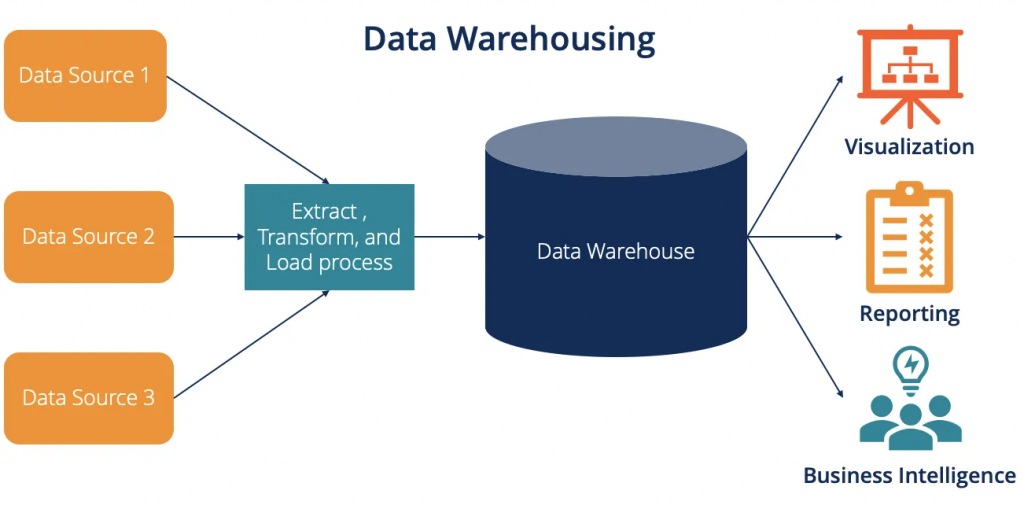
在搭建数仓之前,首先需要明确数据仓库的设计原则。这些原则将指导我们在平衡存储成本和处理效率方面做出正确的决策。
数仓中的数据应该经过清洗、整合和标准化,确保数据质量和一致性。冗余和不一致的数据不仅会增加存储成本,还会影响数据处理和分析的效率。FDL支持多种数据源和目标系统,还支持自定义插件和脚本,用户可以根据自己的需求进行扩展。
根据业务需求和数据分析的目的,确定数据的粒度。过细的粒度会增加数据量和存储成本;过粗的粒度会影响数据分析的准确性。合理确定数据粒度是平衡存储成本和处理效率的关键。
采用合适的数据模型,如星型模型或雪花模型,可以提高数据查询的效率和准确性。同时,在设计数据模型时,要考虑到数据的增长和变化,以便后续的扩展和维护。
为了降低数据存储成本,我们可以采用一些存储优化技术。
将数据按照某个维度进行分区存储,可以降低数据的扫描量,从而提高查询效率。分区可以根据时间、地理位置等维度进行,具体根据业务需求而定。
采用压缩技术可以减少数据的存储空间,从而降低存储成本。常用的压缩技术有字典压缩、位图压缩和列式存储压缩等。选择合适的压缩技术需要考虑数据的结构和查询的特性。
将数据仓库中的数据划分为多个分区,可以根据不同的访问模式来控制数据的存储和访问。通过表分区可以将数据分散存储在不同的磁盘上,提高查询的并行度和性能。
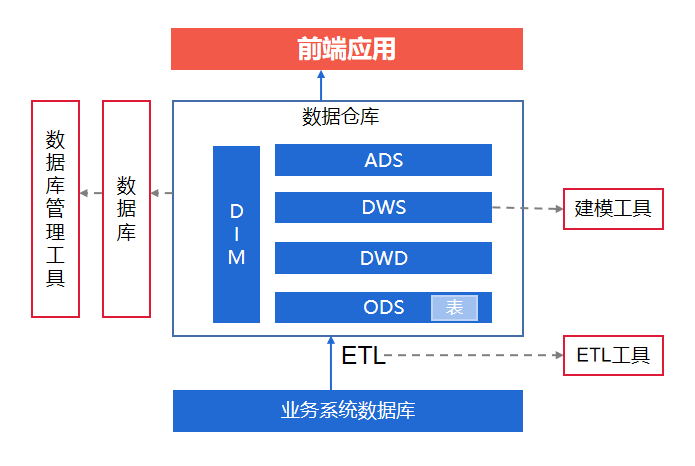
为了提高数据处理效率,我们可以采用一些性能优化方法。
合理创建数据索引可以加速数据的查询和检索。索引可以根据查询的频率和字段的选择性来建立,避免不必要的索引,减少索引的存储开销。
除了存储优化的技术,分区还可以用于数据的处理优化。根据数据的特性,将数据进行分区,可以提高数据处理的效率和并行性。
将数据分布到多个节点中,并通过并行处理技术进行数据处理,可以有效地提高数据处理的效率和吞吐量。FDL提供了强大的数据质量控制功能,包括数据清洗、去重、格式化等,有助于提高数据质量和准确性。
通过缓存机制,可以将频繁访问的数据保存在内存中,以减少对存储系统的访问,提高数据处理的速度和效率。
在数仓搭建过程中,平衡数据存储成本和数据处理效率是一个关键的问题。通过合理的数据存储和处理策略,可以提高数仓的性能和效率,并降低存储成本。在设计数仓时,需要考虑数据合理性、数据粒度和数据模型的设计原则。在实施过程中,可以采用数据分区、压缩技术、索引和缓存机制等存储和处理优化技术。通过权衡各种因素,可以找到数仓搭建中的平衡之道,为企业提供高效和经济的数据存储和处理解决方案。
总而言之,在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink(FDL、好数连)——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据。FDL通过提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
FineDataLink(FDL、好数连)从不同数据源进行离线或实时同步,进一步进行转换、清洗等操作,向任意目标端进行写入,实现任意数据源的数据互通。
帆软推出的FineDataLink(FDL、好数连)是一款低代码/高效率的企业级数据仓库ETL工具,它可以帮助企业快速搭建数据仓库。
数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号