作者:finedatalink
发布时间:2023.9.7
阅读次数:349 次浏览
数据清洗是整个数据分析过程中不可缺少的一个环节,这个环节将重复、多余的数据筛选清除,将缺失的数据补充完整,将错误的数据纠正或去除,从而提升数据质量,提供给上层应用调用。
数据常见的问题可以分成六类“数据缺失值”、”数据值不匹配“、“数据重复”、”数据不合理“、“数据字段格式不统一“、”数据无用“,针对不同的数据问题,我们有不同的应对方法。
(1)对每个字段计算其缺失值比例,然后按照缺失比例和字段重要性,分别制定策略。
(2)不重要的,或者缺失率过高的数据直接去除字段。
(3)重要的数据,或者缺失率尚可的数据,可以进行补全。填充数据可以参考以下方法:
(4)对某些缺失率高,但又很重要的数据,需要和业务人员了解,是否可以通过其他渠道重新取数。
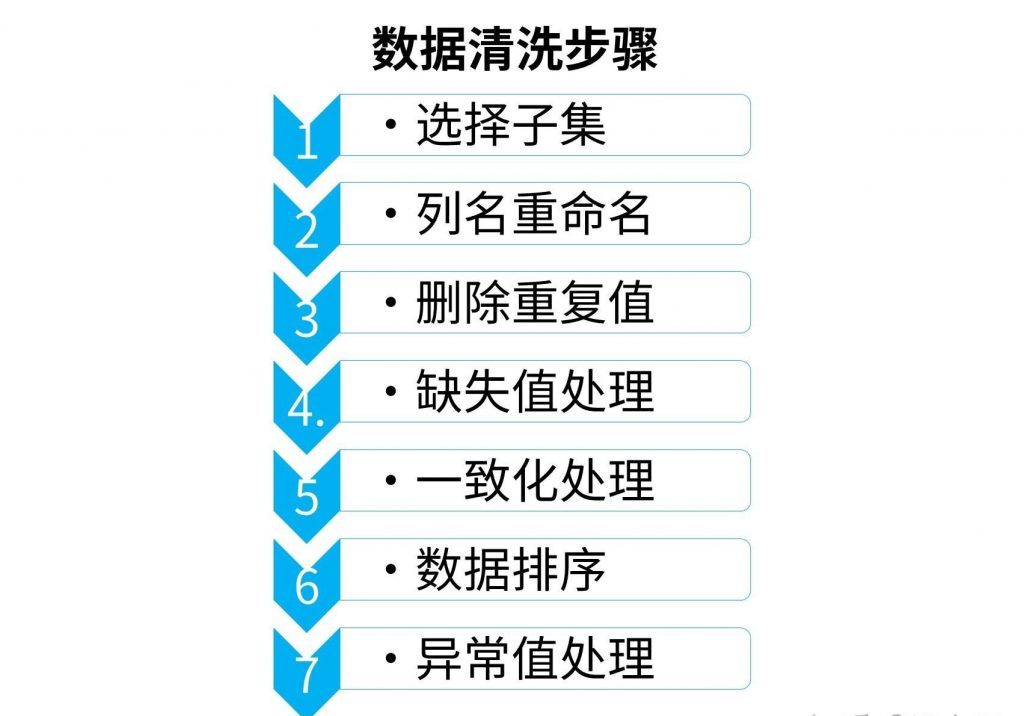
(1)清洗内容中有不合逻辑的字符
最典型的就是头、尾、中间的空格,也可能出现姓名中存在数字符号、出现汉字等问题。这种情况下,需要以半自动校验半人工方式来找出可能存在的问题,并去除不需要的字符。
(2)内容和该字段应有内容不符
经常在处理埋点数据时会发现某个字段内容乱码等,通常过滤掉,但该问题特殊性在于:并不能简单的以删除来处理,因为成因有可能是数据解析错误,也有可能是在数据在记录到客户本地时就发生能了错误(平台),因此要详细识别、分类处理问题。这部分的内容往往需要人工处理,尽量细致地检查,不要遗漏。
数据集中的重复值包括以下两种情况:
(1)数据值完全相同的多条数据记录,这是最常见的数据重复情况。
(2)数据主体相同,但一个属性匹配到不同的多个值。
去重的主要目的是保留能显示特征的唯一数据记录,但当遇到以下几种情况时,不建议去重。
(1)重复记录用于分析演变规律,例如因为系统迭代更新,某些属性被分配了不同值。
(2)重复的记录用于样本不均衡处理,通过简单复制来增加少数类样本。
(3)重复的记录用于检测业务规则问题,代表业务规则可能存在漏洞。
这类数据通常利用分箱、聚类、回归等方式发现离群值,然后进行人工处理。
整合多种来源数据时,往往存在数据格式不一致的情况,将其处理成一致的格式利于后期统一数据分析。
由于主观因素影响,往往无法判断数据的价值,故若非必须,则不进行非需求数据清洗。
可以看到数据清洗的人力成本是比较高的,在真实场景中,数据情况往往会更错综复杂,如果不想经历上述基本的数据清洗手段,可以使用ETL工具来帮助简化数据处理流程,国内ETL产品中做的比较好的有FineDataLink(以下简称FDL)。FDL拥有低代码的优势,通过简单拖拽交互即可实现数据抽取、数据清洗、数据到目标数据库的全过程。
FDL是一款低代码/高时效的数据集成平台,它不仅提供了数据清理和数据分析的功能,还能够将清理后的数据快速应用到其他应用程序中。FDL的功能非常强大,可以轻松地连接多种数据源,包括数据库、文件、云存储等,而且支持大数据量。此外,FDL还支持高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等。使用FDL可以显著提高团队协作效率,减少数据连接和输出的繁琐步骤,使整个数据处理流程更加高效和便捷。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号