 全部案例
全部案例

大数据的商业价值
在DT时代的商业价值链条中,“数据即资产”的概念已经深入人心,一致认为拥有高价值数据源的企业在大数据产业链中占有至关重要的核心地位。大数据产业链发展的下半场,当整个产业链条逐渐做到打通拓宽,形成相对成熟的大数据生态之后,拥有数据源的企业将掌控数据链上游核心资源,并有可能通过数据直接变现迎来新的发展与机遇。 根据《2018全球大数据发展分析报告》显示,中国凭借近几年在“互联网+”与“大数据+”的融合创新,积累了丰富的数据资源,目前中国的大数据产业相关人才数量占比全球最高,达59.5%。其次为美国,占比22.4%。一方面,说明随着云计算建设的深入,大数据理念被用户认可,用户逐渐感受到新技术带来的便利和价值,促进大环境下及早地完善大数据采集的良心发展,避免造成有价值的数据流失;另外一方面,收集了海量的数据管理难度巨大,随之带来数据隐私和数据安全问题,在大数据时代孕育着很多商业机遇的时候,当数据被过度泛滥使用,必将对用户带来巨大的伤害。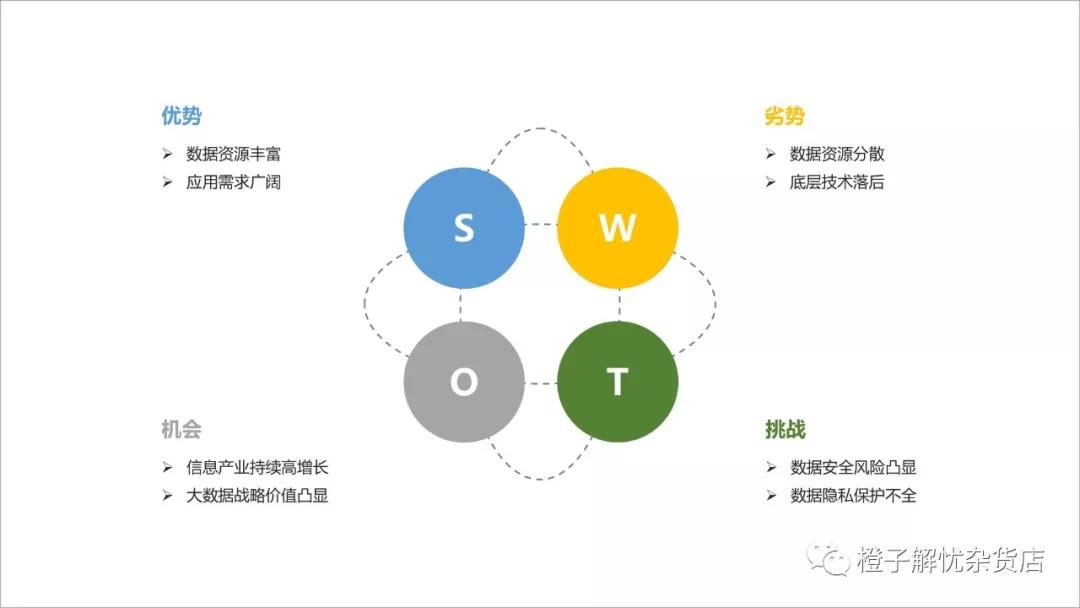
大数据资源SWOT分析图
所以说,随着大数据市场的快速发展,数据资源丰富的同时挑战和机遇是共同存在。为了企业更好的利用大数据赋能业务快速成长,一方面,需要树立正确的数据价值观,对数据要怀有敬畏之心,在保证收集回来数据的安全性和隐私性前提下,合理的存储,不要企图利用数据去作恶;另外一方面,从业务出发合理使用数据,不做数据的独裁者;只有这样才有机会获取新一轮互联网数字化-智能化竞争制高点的“半张船票”。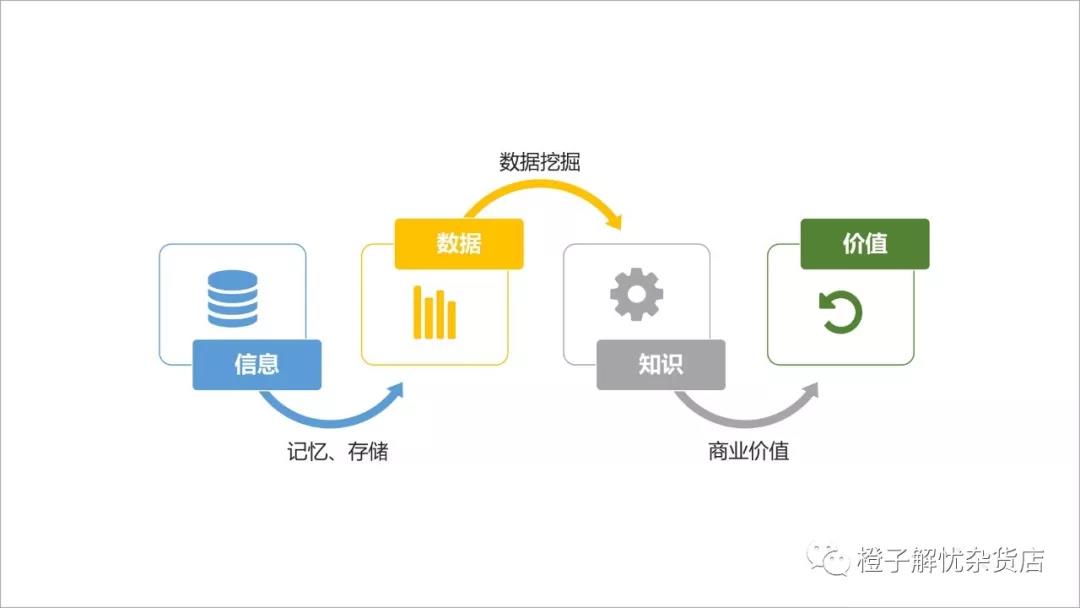
数据价值演变过程图
数据演变成价值,是以数字化的形式先将信息聚合起来,通过记忆、存储的方式变成数据,然后通过数据分析与挖掘的方式变成知识,最后与业务相互结合发挥出商业价值。
通用数据保护条例图
在做数据采集之前,先和大家来谈谈数据安全与数据隐私问题。2018年5月25日,欧洲联盟正式出台《通用数据保护条例》,GDPR生效后,数据安全与数据隐私问题将成为企业必须重视的运营问题。企业必须明确满足数据主体的信息权、获取权、纠正权、限制处理权、反对权、删除权和数据可移动权等。 只有先在数据安全与数据隐私的前提之下,严格按照GDPR的基本原则来收集数据。企业再去明确数据从哪里来,有那些数据,数据存储在什么地方,数据用在什么地方,形成一个完整的数据流向闭环,对每一个信息进行分类,为企业提供一个360度全景的数据地图,才能确保企业能够快速定位、评估和监控所有的数据。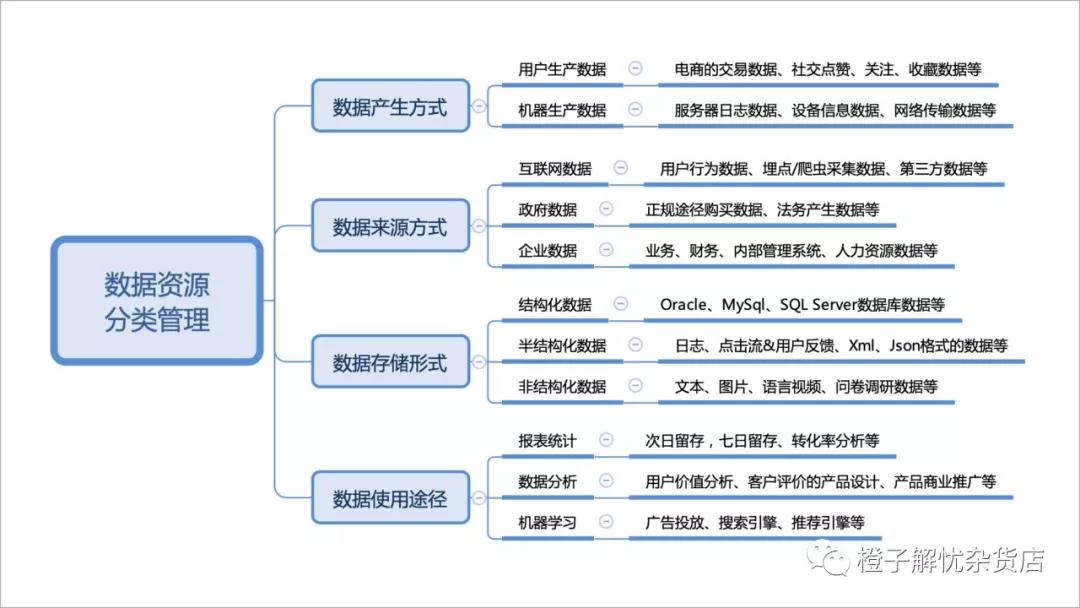
数据资源分类管理图
企业一般会从数据产生方式、数据来源途径、数据存储形式和数据使用用途四个方面对数据进行数据资源分类管理。 从个人实践经验来看,在做数据采集的过程中,规范和流程比设计采集方案更加重要。笔者在做数据采集之前,一般都会先问自己四个问题: 数据模型:日志的数据模型是什么,采集回来的数据怎么做数据归类; 寻找数据:数据从哪里来; 元素采集:需要采集的元素有什么; 采集方式:需要通过什么样的方式收集哪些日志;收集的数据怎么存储,存储在什么地方。 以上四点这些才是数据获取的关键,只有先收集到数据,最后去质量检验。把数据看成矩阵,有矩阵才有输入的模式,才可能获取到相对质量更好的数据。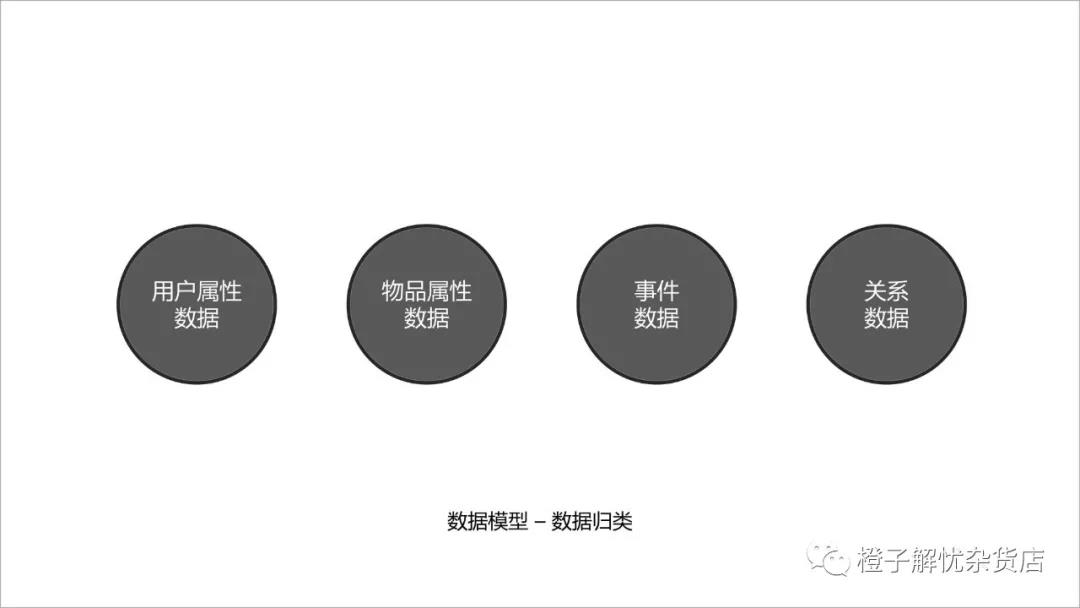
数据模型&数据归类图
一般来说,业内场景化应用无非收集的数据有以下四种:用户属性数据、物品属性数据、事件数据和关系属性。当有了数据模型后,就可以很好地去梳理的数据,看看每一种数据归类是什么样子。 所以,建立数据模型的目的一方面是为了帮助产品梳理数据来源、数据日志、归类存储,以方便在使用时随需获取;另外一方面是为了让使用数据的人员更加透彻的理解业务。在做数据模型的时候,需要提前考虑到模型的延展性、拓展性和解耦性。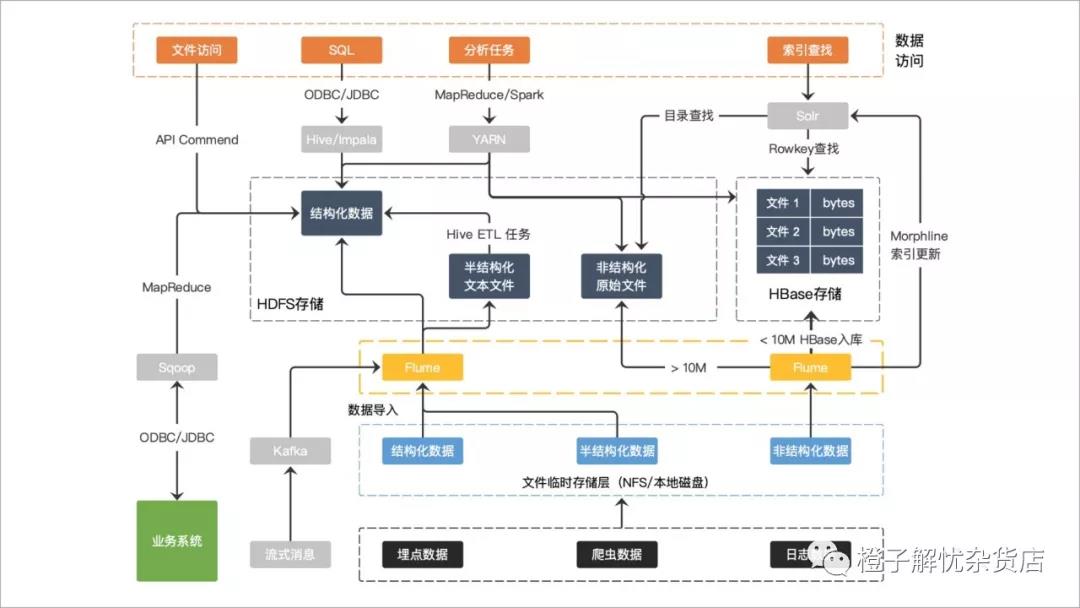
数据采集架构图
从上图,可以衍生在实际数据采集落地工程当中,产品与技术团队会遇到以下几方面的问题: 问题一:产品团队不知道需要采集什么数据 数据采集的最最最基本两大原则:一是全面;二是细致。全面的意思就是需要把可能涉及到业务运转的数据都收集起来,而不只是App端和web端的数据收集;细致的意思就是尽可能多维度收集数据,把事件发生的一系列维度信息,尽量多的记录下来,方便后续做数据分析与挖掘。尽可能的把日志记录想象成一个 Live 快照,当收集的内容越多就越能还原出用户当时使用的场景。 作为产品团队的数据PM,在做需求埋点规划时,一定需要带有目的方式去思考问题,明确知道现阶段数据采集的目的是什么,明白收集数据的目的是做报表统计,是做数据分析还是做机器学习,再基于业务梳理出需要采集数据矩阵是何种形态。只有先明确目标,才能正式开始设计埋点文档。 问题二:产品团队设计的需求埋点混乱,导致出现错埋、漏埋、多埋等的情况 基于业务目标梳理出数据埋点文档,定制好规范和流程。笔者上面说的数据采集的四要素可以入药,在此不多做赘述。 问题三:技术团队不知道通过什么技术手段去采集数据“更好” 好与坏是相对的,没有绝对。无论是采用后端埋点还是前端埋点,都会出现丢包的情况,只能说团队可接受度的范围是多少,心理的阈值是多少,只有先确保埋点数据的完整性、一致性、及时性、准确性等因素,基于业务目的去分析、去平衡要获取什么样的数据,采用什么样的方式去做采集。 另外,有时候不是埋点多就好,这是一个矛盾点。在大数据时代,大数据中的大的对立面就是少,越是真实的业务数据,数据量就越大,可用的信息比例就越少,更多的是噪音数据,如果拟合了噪音数据,那就被数据绑架了。 所以,通过什么技术手段去采集数据“更好”本身就是一个伪命题,只有适合业务目标的采集技术才是相对较好的。同样情况下,无论是产品或者是使用数据的相关人员去做数据分析与挖掘的时候,不要只看数据,更多地从业务本身去思考一下;要活用数据,不要被数据绑架。 问题四:技术团队在数据采集阶段,当做增量同步的时候,遇到可修改、可删除的数据源,如何处理 当在无法确定数据源的情况下,通常会采用:放弃同步,采用直接连接的方式;放弃增量同步,选用全量同步;编写一个定时跑的Job程序,扫描数据源以获得Delta Data,然后对Delta Data进行增量同步三种方式来做数据同步。 但是这三种选择方式其实都算不上最优的选择。如果当数据源的源头可以控制,可以采用监听数据源的变更,然后通过定时跑的Job程序来更新采集的数据,同步存储在数据库中,又有会牵涉到数据存储的选型。 为了更高效地提升数据采集的质量,一般会将整个采集流程切分成多个阶段,在细分的阶段中可以采用多种并行的方式执行。在这个过程中,会涉及到Job的创建、编写、提交与分发,采集流程的规划,数据格式的转换与传输以及数据丢包的容错处理等。 问题五:技术团队,数据采集回来要如何进行合理的存储 根据数据采集获取的日志的时间属性进行合理的存储。通常做法把日志按照日期分区,存储日志在HDFS 中,目的是为了后续抽取方便快速。在存储时,按照前面介绍的数据模型分库分表进行存储,方便后续做数据分析与数据挖掘时准备数据 问题六:产品团队和技术团队需要如何配合 如在博弈中找到平衡点,达到双赢?数据的事情无论是采用自上而下或者自下而上去的方式都可以,当然老板直推的话会好很多,如果平行部门去做数据推动的事情,就会遇到各种不可控的情况。自上而下和自下而上策略的最关键区别在于,前者是一种分解策略而后者是一种合成策略。前者从一般性的问题出发,发问题分解成可控的部分;后者从可控的部分出发,去构造一个通用的方案。 Tips(仅供参考): 在认知上,运用大数据小场景的方式,改变数据相关人员原有的思维模式,知道数据的重要性,重视数据,把数据的优先级提升,改变拍脑袋做决策逐步走向以数据驱动做决策的思维转变; 在沟通上,理性分析问题,把握问题核心痛点,明确跨部门沟通的痛点,先解决主要矛盾,降低双方理解沟通的成本; 从资源上,盘点资源后在合理的时间内安排好双方工作的范围和职责边界。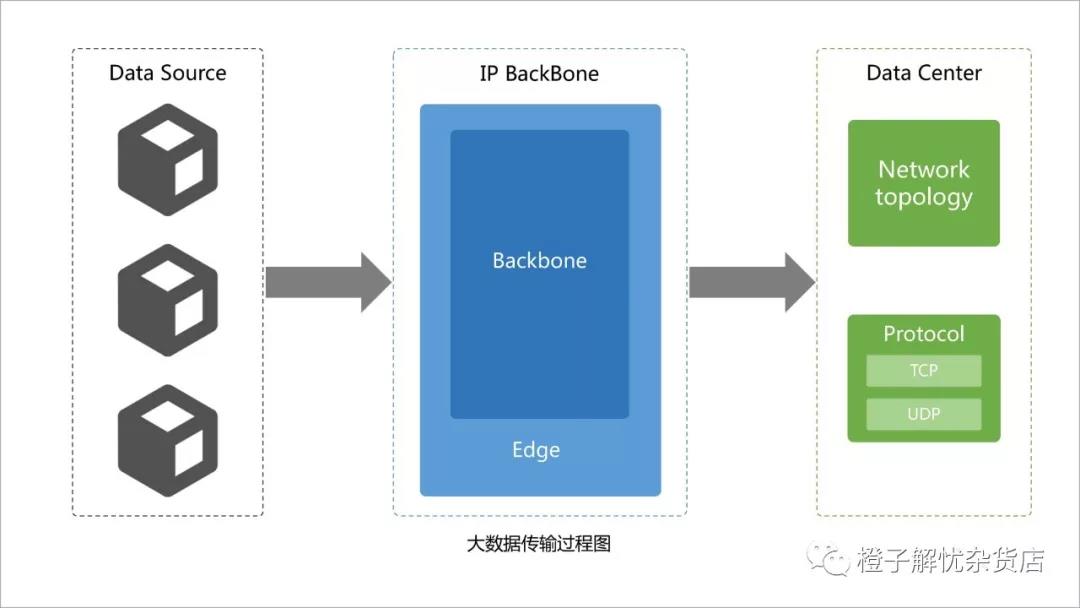
大数据传输过程图
原始数据采集之后必须将其传送到临时存储数据的基础中心等待下一步处理。数据传输过程可以分为两个阶段,IP骨干网传输和数据中心传输。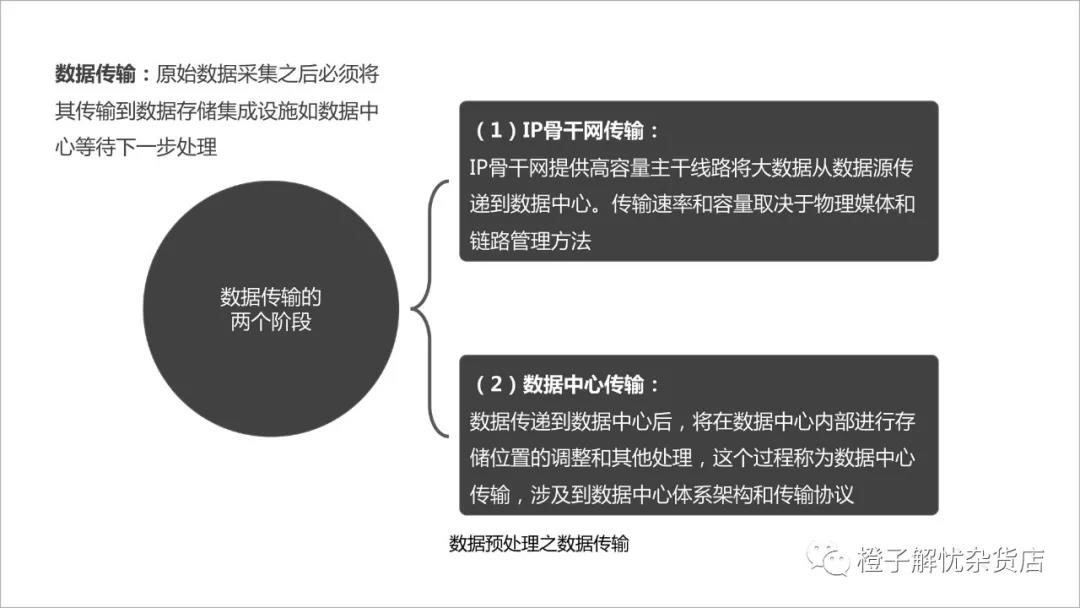
数据预处理之数据传输图
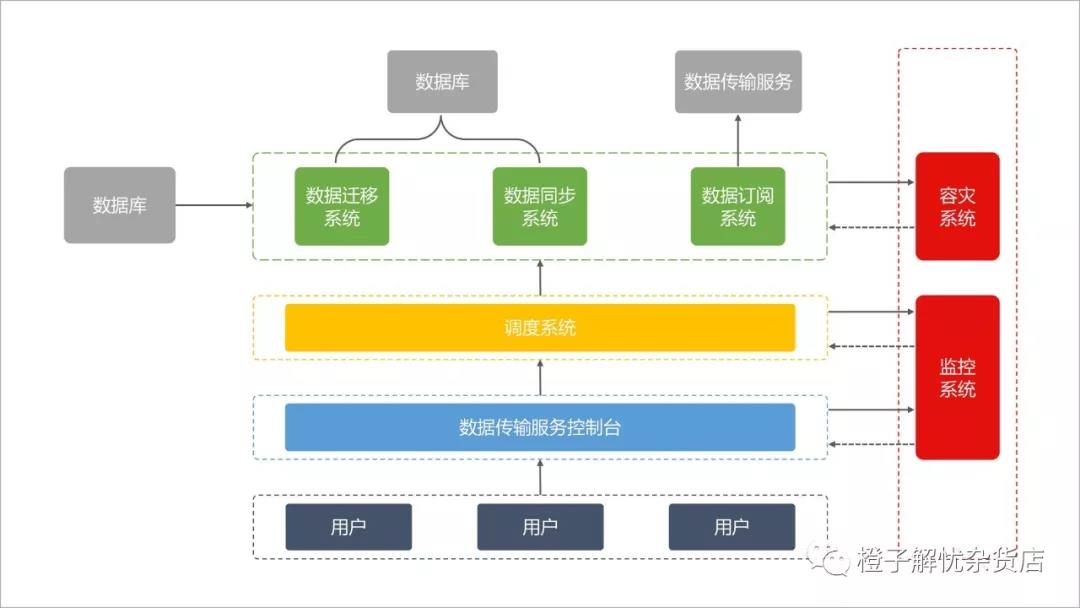
数据传输服务图
数据传输的过程当中,在保证系统的高可用性与数据源动态适配能力的前提下,系统还需要具备数据同步、高性能传输、可视化操作、任务设置简单、故障自动恢复五大能力 保证系统高可用性:在数据传输服务内部的过程当中,保证每个模块都具有主备架构,保证系统高可用性。在容灾系统中对每个节点的健康状况实时监测,当监测到某个节点发生异常情况的时候,会将链路进行秒级切换到其他节点上去 数据源地址具有动态适配的能力:对于数据订阅MQ和数据同步链路,容灾系统对数据源的连接地址切换进行实时监测,当监测到数据源的连接地址发生变更,就会动态适配数据源生产新的连接方式,保证当数据源在发生变更的情况下,数据同步链路的稳定性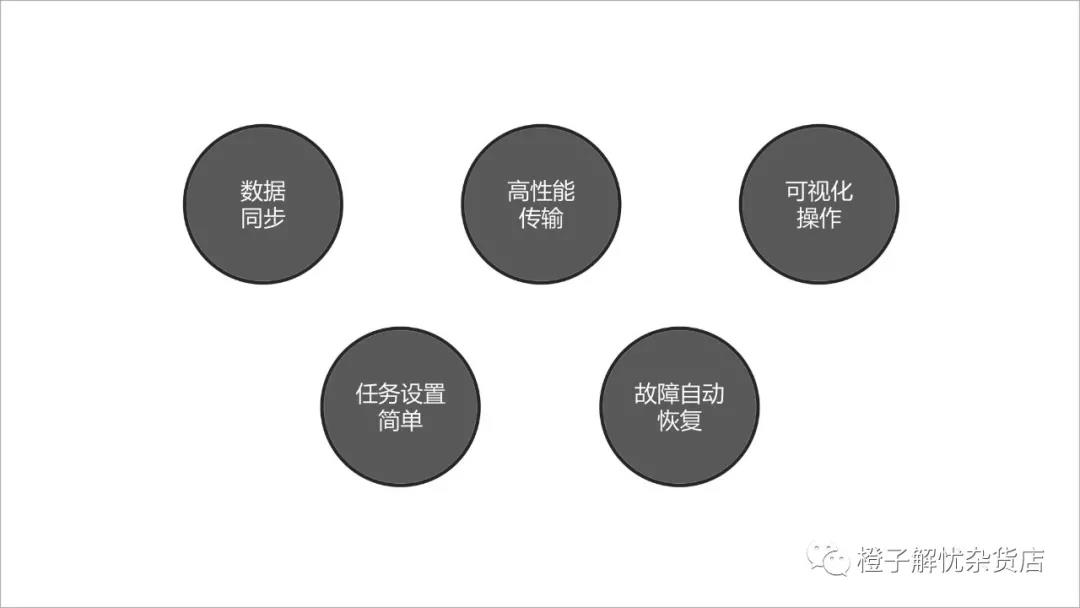
数据传输的五大特性图
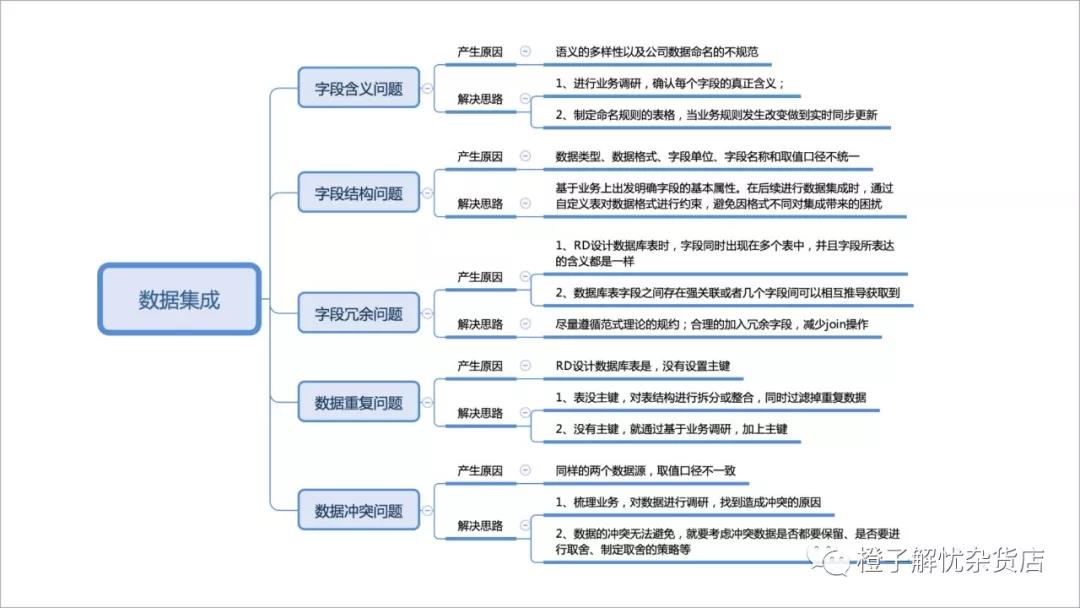
数据集成图
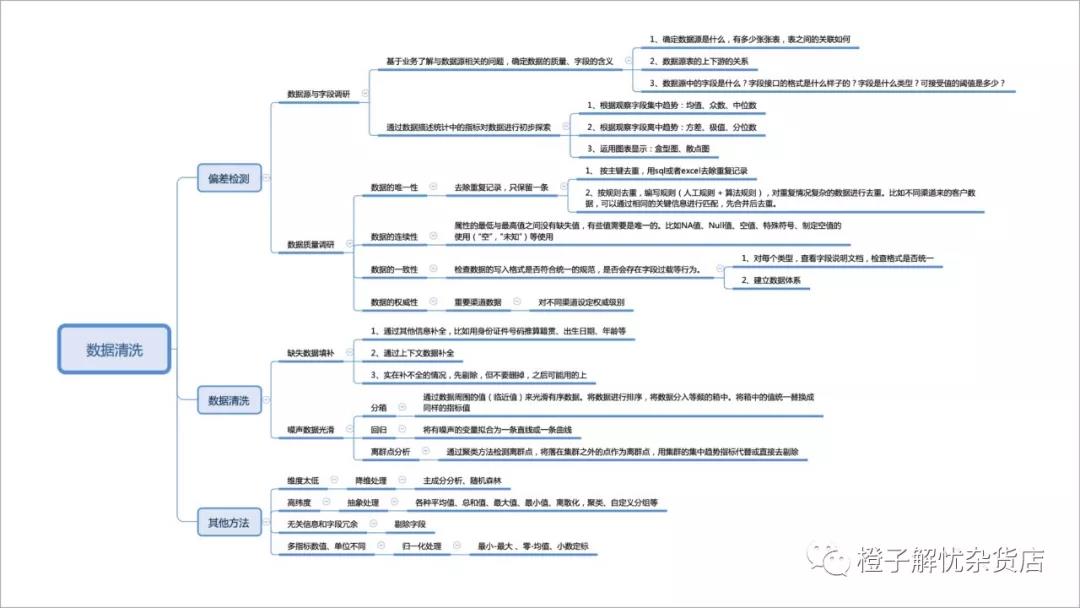
数据清洗图
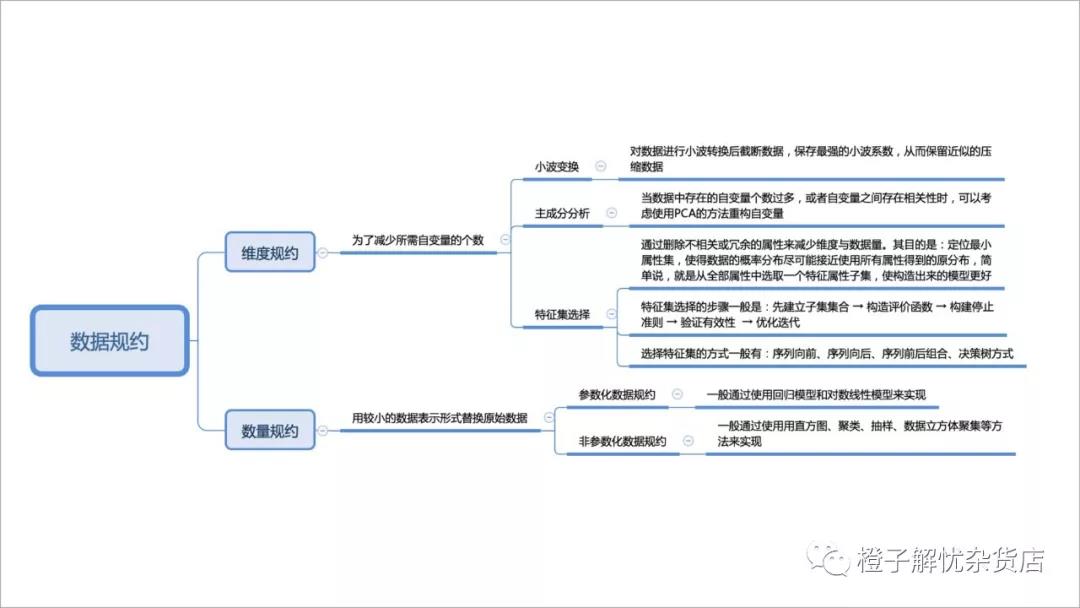
数据规约图
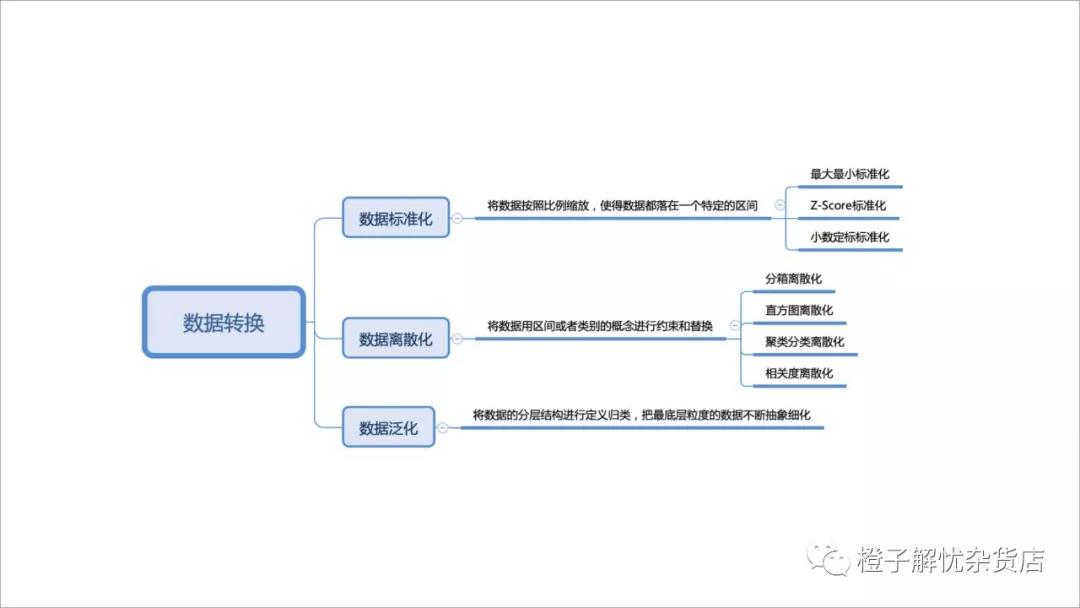
数据转换图


通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。通过FineDataLink作为中间件,简道云数据下云本地化,原库用于提供业务负载,本地库搭配FineReport用于数据分析展示,解决了数据分析人员无法完全取到简道云数据的问题,在FineDataLink侧进行简单的配置,同步数据和附件,即可完成简道云数据的迁移。

整合了MES、ERP、SQS、APS、PLM等系统,建立了公司级别的数据仓库,统一数据源,统一数据分析出口。

FineDataLink和6节点的FineData相结合,自动把4个厂的MES、ERP、WMS、PLM等业务系统,通过数据库logminer、消息等进行实时采集同步;通过对ODS层的数据加工作转换进行分层建设,完成分布式数仓的搭建,10分钟内即可完成从业务库,到ODS的ELT的整个数据链条处理。


 帮助文档
帮助文档 学习视频
学习视频
 苏公网安备32020502001567号
苏公网安备32020502001567号