作者:finedatalink
发布时间:2023.8.10
阅读次数:353 次浏览
在当今互联网时代,随着用户数量的不断增加,系统性能和稳定性成为了开发者关注的焦点。特别是对于需要处理大量数据和并发请求的系统,如何设计一个高可用、高并发的数据集成架构就变得至关重要。
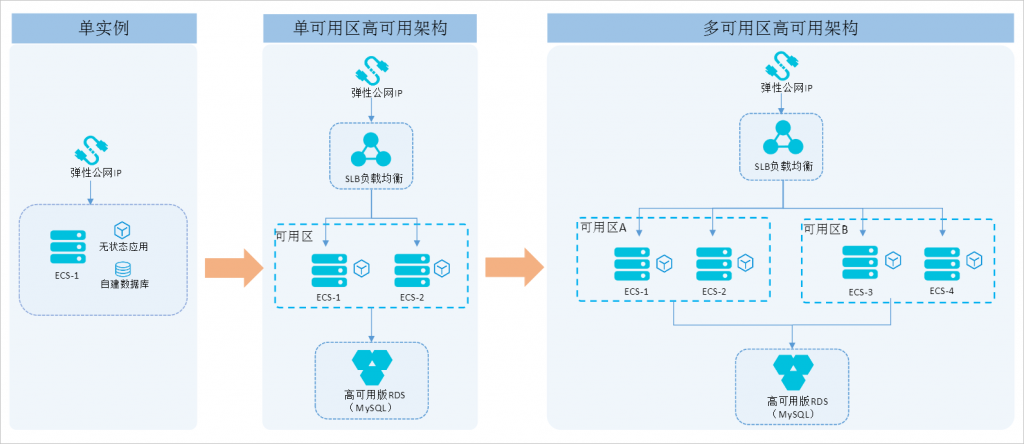
负载均衡是实现高并发的关键步骤之一。通过将流量均匀地分发到多个服务器上,可以提高系统的并发处理能力。常用的负载均衡算法有轮询、随机、最少连接等,开发者可以根据系统的特点进行选择。
为了提高系统的可用性和容灾能力,使用分布式存储是十分必要的。将数据分散存储在多个节点上,可以避免单点故障导致的系统崩溃。同时,分布式存储还能提供更高的读写性能。
消息队列可以对请求进行解耦,实现异步处理。通过消息队列,可以将请求放入队列中,再由后台异步处理,提高系统的并发能力。消息队列还可以实现削峰填谷,将请求高峰期的流量放入队列中,避免对系统的冲击。
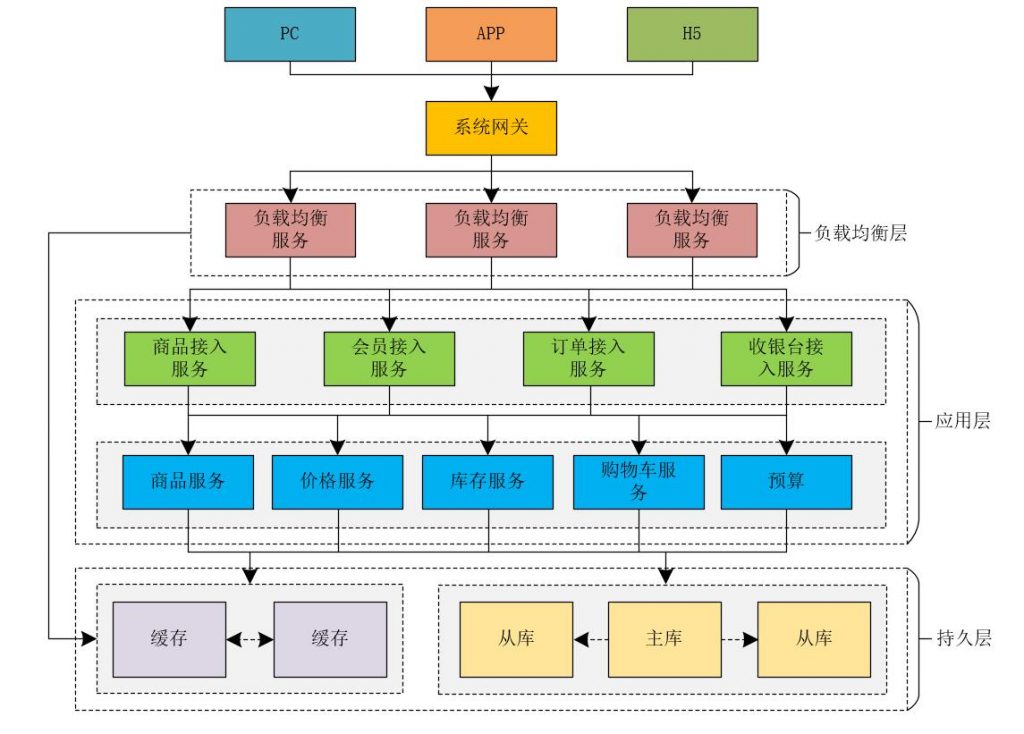
对于频繁访问的数据,使用缓存可以大大提高系统的性能和吞吐量。缓存可以存储经常使用的数据,减少数据库的访问压力。常见的缓存技术有Redis、Memcached等,可以根据实际需要选择。
为了保障系统的稳定性,监控系统的运行状况,并及时发现故障是至关重要的。通过引入监控系统,可以对系统进行实时监测,并及时发出警报,对故障进行快速定位和处理。此外,还可以通过引入自动恢复机制,实现对故障的自动修复,提高系统的可用性。
在构建高可用高并发集群的数据集成架构过程中,需要根据具体的业务场景进行设计。以上只是介绍了一些常用的方法和技术,开发者还需根据实际情况进行合理的选择和搭配。通过合理的架构设计和技术选型,才能够更好地提升系统的性能和稳定性,为用户提供更好的服务体验。
在解决端到端异构数据问题的同时,FineDataLink追求更优的性能体验和更高的稳定性,FineDataLink基于系统、用户配置,结合自调优的内存管理和并发控制,加上了高可用/高并发集群,几乎不会出现运行过程中的高负载和宕机问题。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 断点续传技术:改变文件传输的未来趋势下一篇: 带你构建高可用高性能数据集成集群架构!


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号