作者:finedatalink
发布时间:2023.8.15
阅读次数:679 次浏览
随着互联网和各种通信技术的迅猛发展,大数据已经成为当今科技领域的重要研究方向之一。然而,随之而来的是大数据集成和处理的挑战。大数据集成涉及多个来源和格式的数据,而大数据处理则需要高效的算法和工具来提取有用的信息。本文将探讨这些难题,并提供解决方案和案例分析。

大数据往往来自不同的数据源,包括数据库、文件、Web等。面对这些多样的数据源,传统的数据集成方法已经无法应对。解决方案之一是采用数据仓库或数据湖的架构,将所有数据存储在统一的位置,并通过数据虚拟化技术来实现数据集成。
不同数据源往往使用不同的数据格式,如关系型数据库、XML、JSON等。为了解决数据格式异构性带来的问题,可以使用ETL工具(提取、转换、加载)来进行数据格式转换和数据清洗。
大数据集成过程中常常会遇到数据质量不高的情况,如缺失数据、错误数据等。为了提高数据质量,可以使用数据质量工具进行数据清洗和数据验证,并采用数据监控和数据治理的方法来确保数据的准确性和完整性。
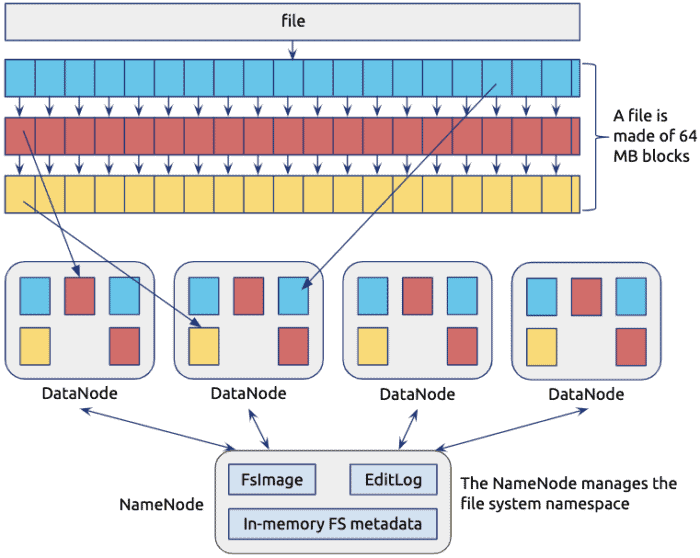
大数据处理面临的第一个挑战是数据量巨大,常常需要处理PB级甚至EB级的数据。为了高效处理大数据,可以采用分布式计算技术,如Hadoop、Spark等,并使用并行算法来提高计算速度。
在处理大数据时,常常需要实时或近实时地处理数据。为了满足处理速度的要求,可以使用流计算技术,如Flink、Storm等,以及内存数据库和缓存技术来提高数据处理的效率。
大数据处理往往涉及复杂的计算任务,如数据挖掘、机器学习等。为了应对这些复杂的计算任务,可以使用分布式机器学习框架来进行模型训练和预测。
以下是两个成功解决大数据集成与处理难题的案例:
某公司面临多个不同的数据源,包括数据库、文件和Web数据。为了解决数据集成问题,该公司采用了数据仓库的架构,将所有数据存储在统一的地方,并使用数据虚拟化技术来实现数据集成。通过这种方式,他们实现了数据的集成和整合,提高了数据质量和决策的准确性。
一家电商公司需要对大量的用户行为数据进行实时分析和推荐。为了满足处理速度和数据规模的要求,他们采用了Hadoop和Spark等分布式计算技术,并使用流计算技术进行实时处理。通过这种方式,他们成功地提高了数据处理的效率和准确性,从而改善了用户体验。
大数据集成与处理是当前科技领域的重要课题,在面对如此庞大和多样的数据时,我们必须克服各种难题,并应用先进的技术来提高工作效率和数据质量。通过本文的介绍和案例分析,我们可以看到有效的解决方案可以帮助我们克服大数据集成与处理的难题,并在实际应用中取得成功。
使用数据集成工具FineDataLink,可以转化不统一或质量低的数据,还可以将数据清洗和处理集中完成,将数据整合到数据仓库。减少数据连接和错误重试等繁琐的开发时间。完成数据清洗后,结果表会同步至数据库内,方便其他应用快速调用。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号