作者:finedatalink
发布时间:2023.7.26
阅读次数:272 次浏览
数据仓库治理是一个复杂而又困难的过程。在实际应用中,数据仓库的数据来源零散,企业内部的各个团队也存在着不同的数据规范和管理方式,这无疑增加了数据仓库治理的难度。另外,在数据仓库的建模过程中,模型的治理难度也远大于架构,尤其是当业务需求模糊不清时。
构建数据仓库通常采用自下而上的方式,通过逐层建立各种维度表和事实表等基础模型,最终形成完整的数据仓库模型。但是,如果设计者对领域模型不熟悉,或者业务发生了变动,数据仓库重构就会变得困难重重。

为了解决这些问题,一些公司(如阿里巴巴)会采用更进一步的工作方法,例如模型的健康分析,来评估数据仓库的综合性能、存储成本和计算成本等。但是,这只能发现一些常规的问题,而不能替代人工治理。
因此,数据仓库治理是一项需要不断投入和维护的任务。在建立完整的数据模型基础上,需要进行人工治理和优化,以提高数据质量和可靠性。同时,还需要随时注意业务需求和数据变化,以及采用新技术和数据治理工具进行数据分析和处理。

在建立数据仓库的过程中,需要建立基于维度模型的数据仓库建设方法,并在此基础上对业务和数据域进行分析。
1. 宏观了解数据的统计周期,确定全量同步或增量同步,并根据预估的数据量设计数据仓库ODS层。
2. 在业务域划分后,构建最明细粒度的事实表DWD,基于DWD构建公共粒度的汇总指标事实表DWS。
3. 如果存在复杂业务逻辑,则避免加工到DWD中,在ADS层进行处理。
4. 定义一致性的维度DIM,用于支持各种不同的分析和业务需求。
在建模的过程中,需要注重模型的评审和进行CodeReview,以及持续投入和不断优化,以确保数据仓库的质量、一致性和效率。另外,在建设好公共层之后,应该避免频繁修改引发后续维护问题。只有建立了稳固的基础之后,才能进行ADS层的业务开发和数据分析。

建模方法只是数据处理中的一部分,还有其他需要注意的地方:
1. 数据的命名和结构:数据的命名和结构会直接影响到数据的可维护性和可扩展性应该,避免使用过于简略的缩写。
2. 表的依赖层级:通过合理的分区和使用临时表,可以降低表的依赖关系,提高查询效率和并行度。
3. 延伸字段的存储方式:除了key-value的形式,还可以使用json、protobuf等格式进行存储。
4. 精度问题:应该避免使用不精确的类型。例如在处理金额等数据时,使用Decimal类型会更加可靠和精确。
5. 空值处理:避免空值对数据处理的影响。

通常而言,数据问题的检测有以下方式:
1. 基于统计:根据规范编码便可以清晰地进行统计,对数据仓库的整体建设情况有大致了解。
2. 基于自动规则:可以进一步提高数据问题的检测和解决效率。这种方式通常包括规则引擎和自动化工具的应用。
3. 基于价值衡量:只有找到数据表的价值和成本,才能更好地规划数据仓库的建设和维护。无论是优先治理高价值的场景还是寻找低价值的重构点,都需要在数据表的价值和成本基础上进行决策。
最后,数据治理工具的应用也是非常关键的。通过数据治理工具的自动化处理,可以节省时效、提高数据治理的效率和精度,减少人为误判和错误。
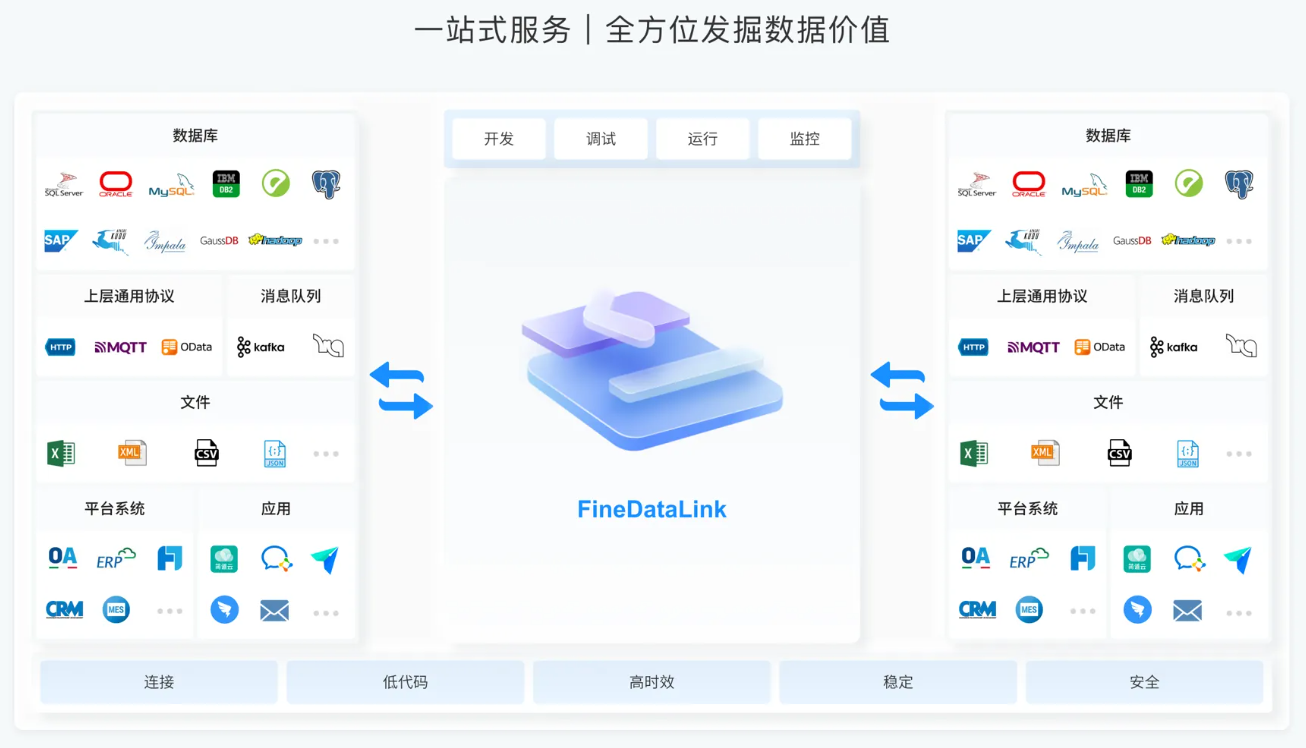
备受市场认可的数据治理工具其实有很多,选择时必须要结合实际的情况。帆软推出的ETL工具——FineDataLink能够帮助企业构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。同时,FineDataLink也支持开放API和服务接口,可以与其他数据工具和系统进行整合和拓展。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 扫盲系列:详解数据仓库的实施步骤下一篇: 多源异构数据融合真不难!用这个工具轻松搞定!


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号