作者:finedatalink
发布时间:2023.8.16
阅读次数:452 次浏览
个性化数据处理在当今的技术发展中扮演着至关重要的角色。随着大数据时代的到来,处理海量的数据变得越来越重要,而每个企业、组织、甚至个人对于数据的需求也都是不同的。为了满足个性化的数据处理需求,插件引擎应运而生。本文将深入研究插件引擎如何支持用户定制化的数据处理策略,以及其在个性化数据处理流程中的具体应用。
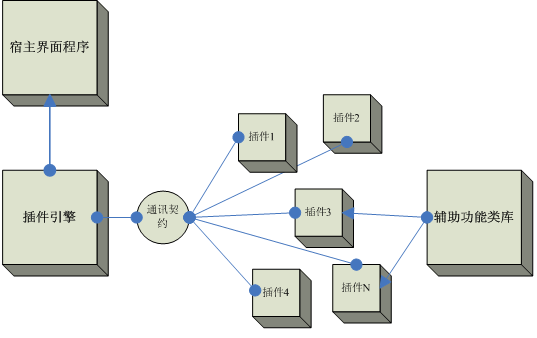
插件引擎是一种软件架构,用于扩展和定制现有软件功能。它允许用户通过增加、修改或删除插件来自定义软件的行为,从而满足不同的需求。在个性化数据处理中,插件引擎起到了非常重要的作用,使数据处理过程能够根据用户的需求进行定制。

数据清洗是个性化数据处理中的重要环节。不同的用户对于数据的质量要求可能有所不同,插件引擎可以支持用户自定义的数据清洗策略。用户可以通过添加、删除或修改特定的清洗插件来完成数据的清洗工作,从而满足个性化的数据处理需求。
数据转换也是个性化数据处理中的一个关键步骤。不同的用户需要将数据转换为不同的格式或结构,以适应其特定的需求。插件引擎可以支持用户自定义的数据转换策略,通过增加、修改或删除特定的转换插件来实现数据的转换。
个性化数据处理中的数据分析是根据用户特定的需求进行的。插件引擎可以支持用户自定义的数据分析策略,通过增加、修改或删除特定的分析插件来实现数据的分析。用户可以根据自己的需求选择合适的分析插件,从而获取到所需的分析结果。
插件引擎具有灵活性和可扩展性,使用户能够根据自己的需求来定制数据处理流程。它可以满足不同用户的个性化需求,提高数据处理的效率和准确性。
插件引擎的设计和实现需要考虑到安全性和稳定性等方面的问题。此外,对于非技术人员来说,使用插件引擎进行个性化数据处理可能具有一定的学习曲线和难度。
个性化数据处理是当今科技发展的趋势,插件引擎作为一种支持用户定制数据处理策略的技术架构,具有重要的作用。通过合理利用插件引擎,用户可以根据自己的需求定制个性化的数据处理流程,从而提高数据处理的效率和准确性。然而,插件引擎的设计和实现仍面临一些挑战,需要在安全性和稳定性方面进行考虑。未来,随着技术的进一步发展,插件引擎将在个性化数据处理领域发挥更大的作用。
FineDataLink是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业快速构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。FDL在进行iPaaS领域的尝试,结合流批一体引擎、流程调度引擎,打造具有帆软特点的集成平台,通过全新的插件引擎,能够极大程度让用户自定义各类数据源的同步、计算、流程控制和调度策略。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号