作者:finedatalink
发布时间:2023.8.10
阅读次数:342 次浏览
在数字时代,企业对于数据的依赖程度愈发显著。然而,随着数据规模不断增大,数据处理的稳定性和高效性变得不可忽视。构建一个稳定的数据处理生态系统,已经成为企业保障数据管理的重要任务。本文将深入探讨如何通过高可用性架构和自动化调优技术,为企业打造一个可靠的数据处理生态系统,保障数据的连续性和高效性。
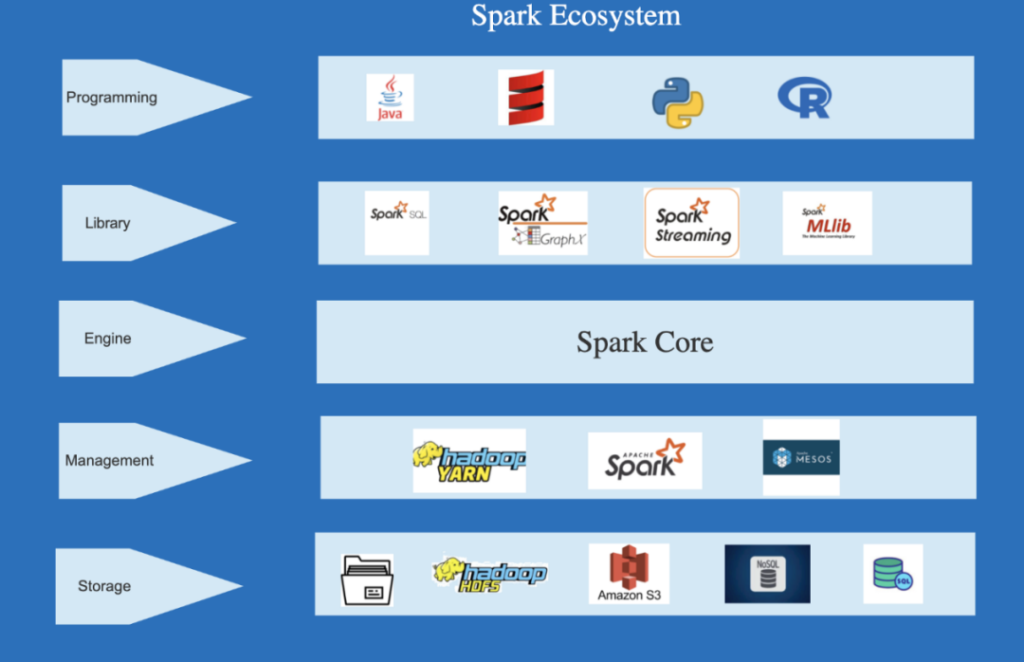
为了应对数据处理过程中可能出现的各种挑战,高可用性架构成为构建稳定数据处理生态系统的关键支柱。在高可用/高并发集群架构中,系统具备备份和容错机制,即使在某个节点发生故障时,其他节点仍能继续工作,确保数据处理流程的持续运行。这种架构不仅降低了宕机的风险,还提供了即时的切换能力,保障数据处理的稳定性。
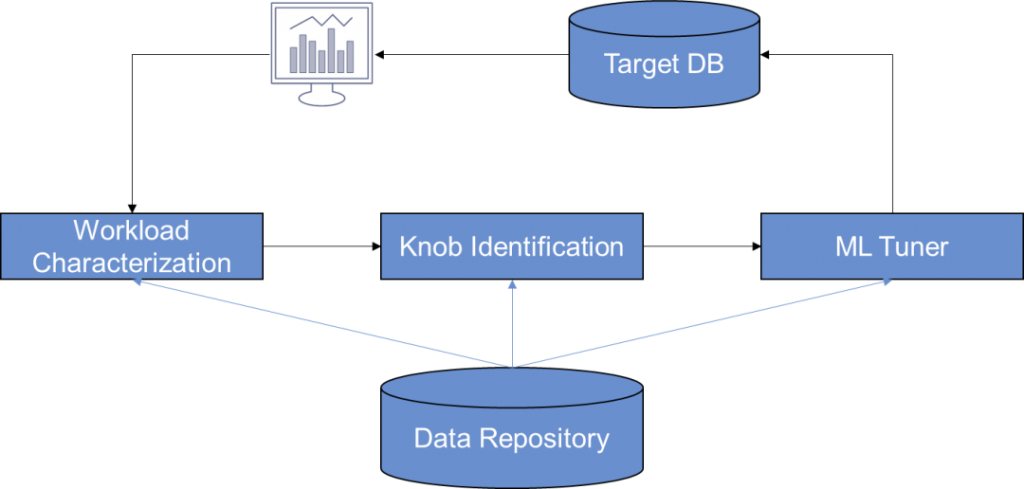
为了实现稳定性和高效性,自动化调优技术扮演着重要角色。自动内存管理和并发控制技术,可以根据系统和用户的配置,智能地分配内存资源,确保在高负载情况下仍能保持良好的性能表现。这种智能化的调优方式大大降低了人工干预的需求,同时最小化了系统宕机的风险,为数据处理提供了稳定的基础。
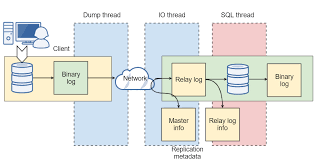
在企业数据处理中,数据流的连续性至关重要。稳定的数据处理生态系统能够保障数据从源头到目标的顺利流动,避免中断和延迟。高可用性架构的保障和自动化调优的支持,使得数据在高负载情况下依然能够连续流动,确保数据处理的高效性。
在构建稳定的数据处理生态系统方面,FineDataLink为企业提供了完美的解决方案。我们基于系统、用户配置,结合自调优的内存管理和并发控制,加上了高可用/高并发集群,几乎不会出现运行过程中的高负载和宕机问题。帮助企业确保数据的稳定性和连续性,提升数据处理的效率。欲了解更多详情,点击免费获取更多信息。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 断点续传的实用技巧你了解多少?下一篇: 数据追踪技术:揭开用户行为分析的神秘面纱


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号