作者:finedatalink
发布时间:2024.7.30
阅读次数:102 次浏览
增量同步,又称为差异同步,是指只传输自上次同步以来数据库中发生变更的数据。这种同步策略可以显著减少数据传输量,加快同步速度,尤其适用于大规模数据库之间的同步。
增量同步的原理主要是通过记录数据的变化日志,通常称为变更捕获Change Data Capture(CDC),将变更日志传输到目标数据库,然后根据日志中的信息还原出变更前的数据状态。这种方法能够有效地减少数据传输量,同时避免重复传输相同的数据。

在需要实时获取数据变更并进行处理的场景,如实时交易、监控系统等,增量同步可以快速同步数据变更,满足时间效率要求。
对于拥有大量数据的数据库,增量同步可以提高数据同步的效率,因为它只同步变化的部分,而不是整个数据库。
在数据库迁移过程中,全量迁移结合增量同步功能可以平滑迁移数据库,完成数据对象异构迁移与数据迁移,并持续跟踪采集源库变更,进行增量的数据同步,有效缩短停机窗口,降低迁移风险。
增量同步可以实现异构关系数据库之间的实时单向数据同步、双向数据同步、数据共享等,满足在不同应用程序之间分布和整合数据的需求。
增量同步可以用于定期备份数据库的变更,以便在数据丢失或损坏时快速恢复到最新状态。
数据仓库通常需要定期更新以反映源系统中的数据变更,增量同步可以确保数据仓库中的数据是最新的,同时减少处理和存储的开销。
在分布式系统中,增量同步可以保持不同节点之间的数据一致性,尤其是在节点独立更新数据时。
随着云计算的普及,增量同步可以用于同步云服务中的数据到本地系统,或者反之,以保持数据的一致性。
下面为大家带来一份使用FineDataLink进行增量更新的案例:
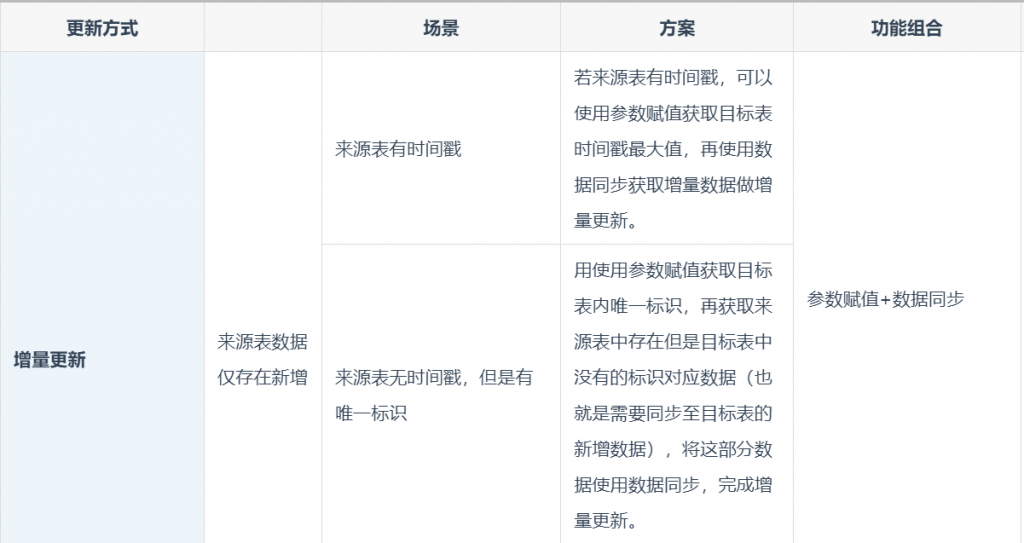
若来源表有时间戳,可以使用「参数赋值」节点获取目标表时间戳最大值,再使用「数据同步」节点获取增量数据做增量更新。
来源表为 demo_ods_huabeicaiwu ,目标表为 dw_caiwu ,都包含时间戳「订单生成时间」。如下图所示:
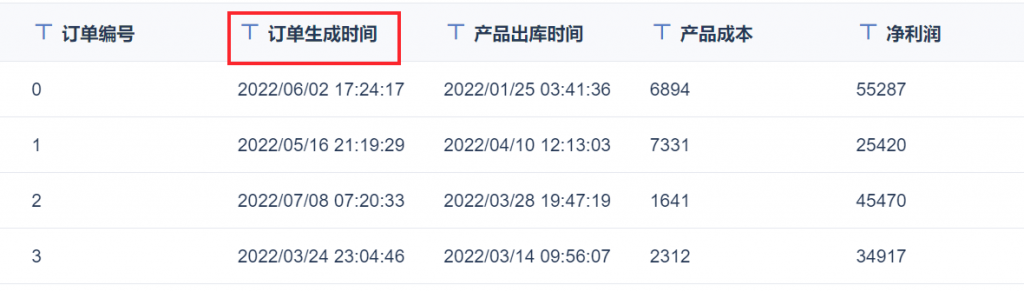
若目标表中「订单生成时间」的最大值,小于来源表的「订单生成时间」,说明来源表存在新增数据,需要将新增数据同步到目标表中。
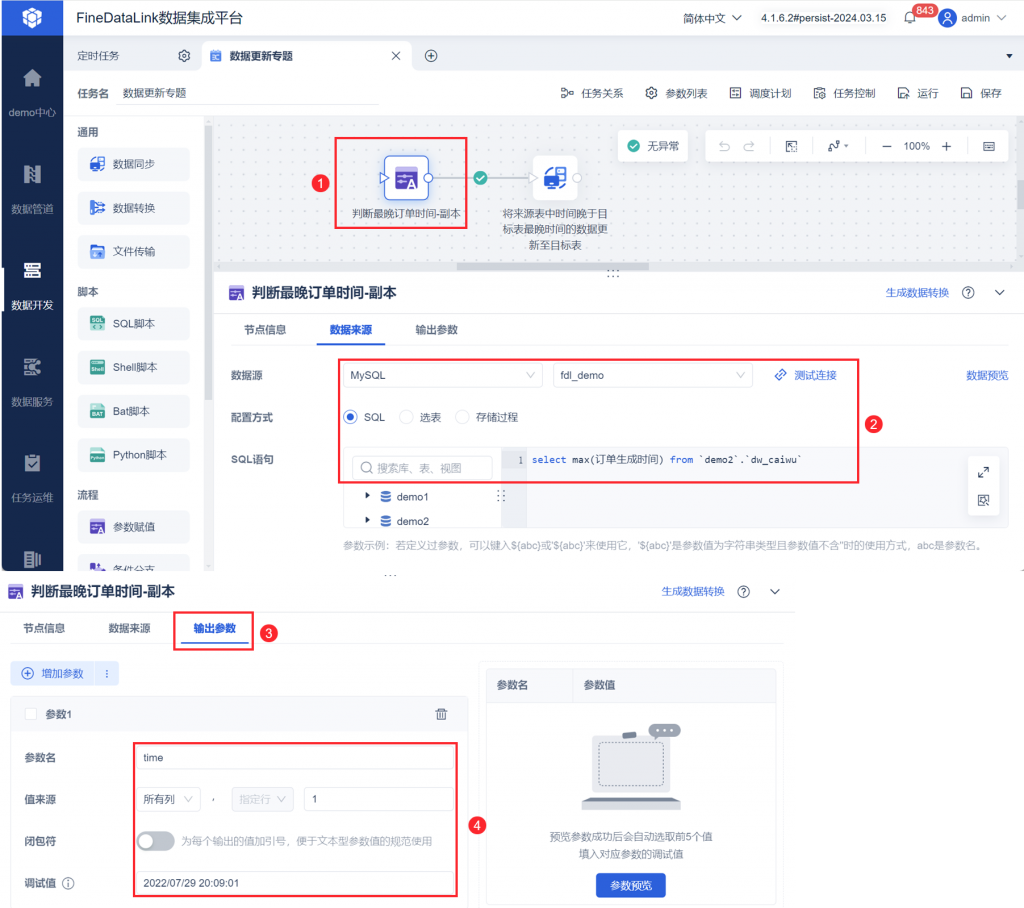
使用「参数赋值节点」节点,取出目标表中「订单生成时间」的最大值,将其设置为 time 参数。如下图所示:
1)拖入一个「数据同步」节点,与「参数赋值」节点相连。
2)「数据同步」节点中,将来源表「订单生成时间」大于 time 参数的数据取出,同步到目标表中。如下图所示:
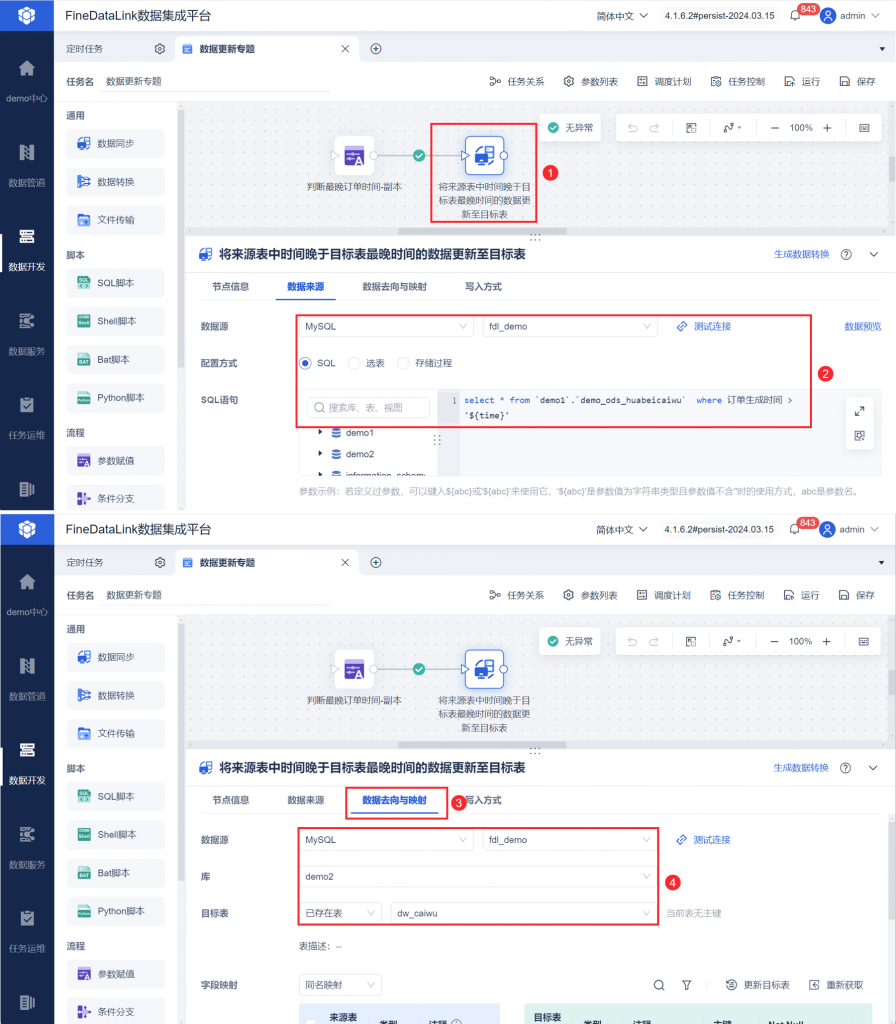
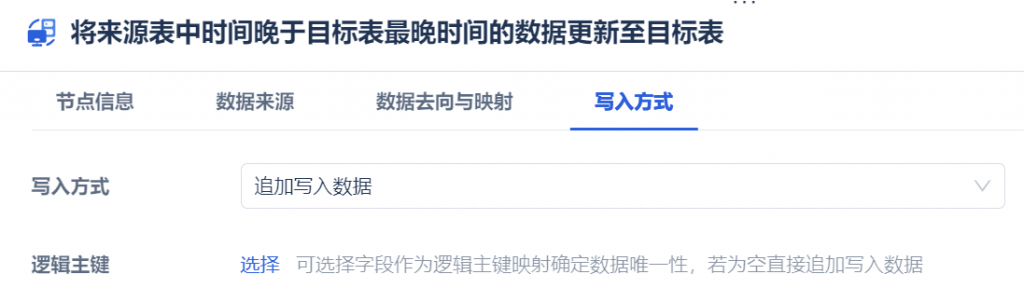
3)由于同步的数据是新增数据,追加写入数据即可;逻辑主键可不设置,为空表示直接追加写入数据。如下图所示:
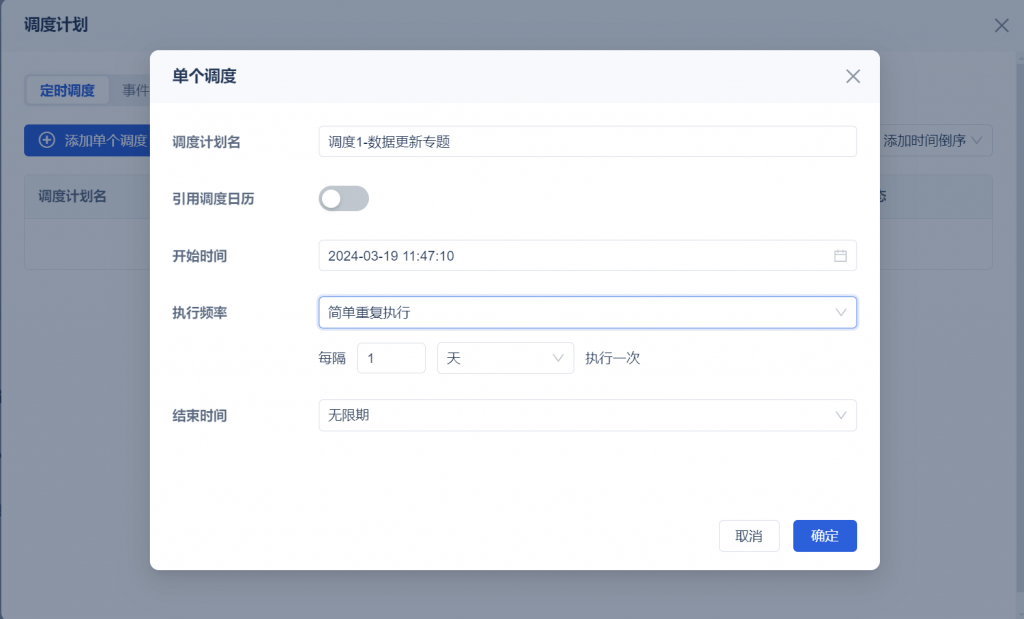
4)可设置定时任务的执行频率,例如若希望每天将新增数据同步到目标表中,可设置一天执行一次。
点击右上角「调度计划」按钮,设置执行频率。如下图所示:
FineDataLink,它小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,应有尽有,功能很强大。最重要的是,因为这个工具,整个公司的数据架构都可以变得规范。而且它是java编写的,类流程图式的ETL开发模式,上手都很简单:数据对接、任务复用简直都是小case,大大降低了数据开发的门槛。在企业中被关注最多的任务运维,FineDataLink大运维平台,支持文件夹式开发模式,报错任务可一键直达修改,报错优化清晰易懂;通过权限控制,保障系统安全。
FineDataLink,它小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,应有尽有,功能很强大。最重要的是,因为这个工具,整个公司的数据架构都可以变得规范。而且它是java编写的,类流程图式的ETL开发模式,上手都很简单:数据对接、任务复用简直都是小case,大大降低了数据开发的门槛。在企业中被关注最多的任务运维,FineDataLink大运维平台,支持文件夹式开发模式,报错任务可一键直达修改,报错优化清晰易懂;通过权限控制,保障系统安全。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 增量同步时该如何确保数据的一致性和完整性?这款工具告诉你答案下一篇: 跨库取数跨库取数需要复杂编程怎么办?推荐这款低代码ETL工具


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号