作者:finedatalink
发布时间:2024.7.30
阅读次数:918 次浏览
数据清洗是数据治理过程中的一个重要环节,它指的是对原始数据进行筛选、修复、转换和处理,以确保数据的准确性、完整性和一致性。
在数据清洗过程中,不仅需要明确数据清洗的对象,还需要根据具体的情况选择合适的数据清理方法。以下是不同对象所对应不同的数据清洗方法。
数据清洗旨在发现并纠正数据文件中可识别的错误,包括检查数据一致性、处理无效值和缺失值等。以下是数据清洗的一些主要方法:
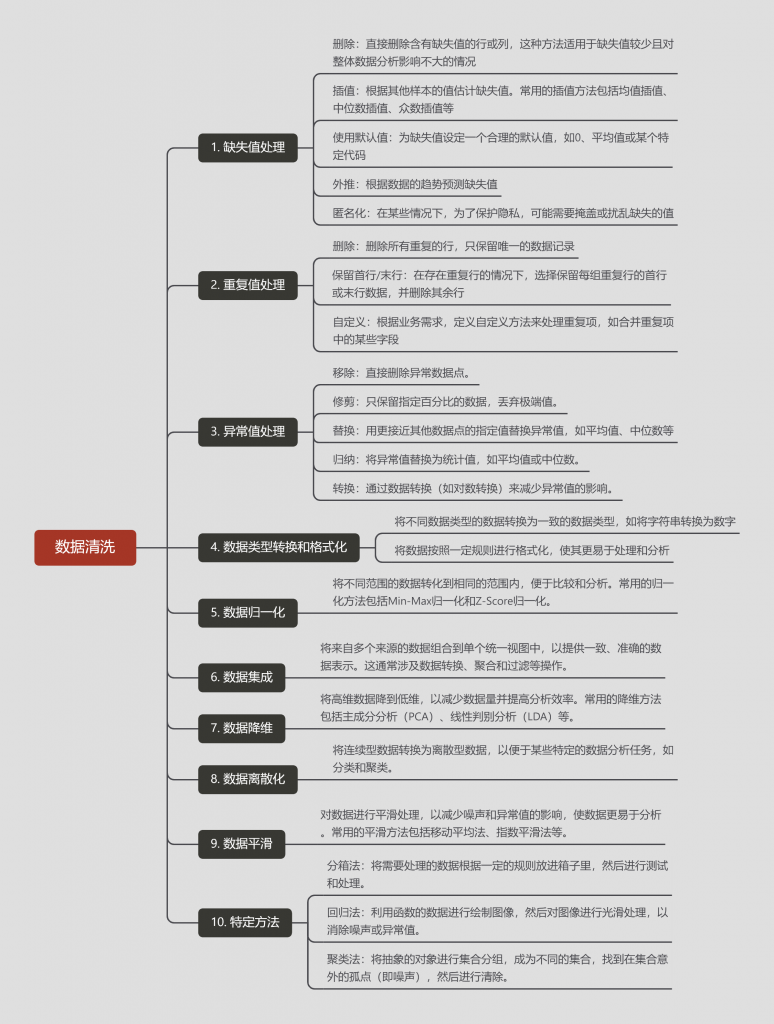
删除:直接删除含有缺失值的行或列。这种方法适用于缺失值较少且对整体数据分析影响不大的情况。
插值:根据其他样本的值估计缺失值。常用的插值方法包括均值插值、中位数插值、众数插值等。
使用默认值:为缺失值设定一个合理的默认值,如0、平均值或某个特定代码。
外推:根据数据的趋势预测缺失值。
匿名化:在某些情况下,为了保护隐私,可能需要掩盖或扰乱缺失的值。
删除:删除所有重复的行,只保留唯一的数据记录。
保留首行/末行:在存在重复行的情况下,选择保留每组重复行的首行或末行数据,并删除其余行。
自定义:根据业务需求,定义自定义方法来处理重复项,如合并重复项中的某些字段。
移除:直接删除异常数据点。
修剪:只保留指定百分比的数据,丢弃极端值。
替换:用更接近其他数据点的指定值替换异常值,如平均值、中位数等。
归纳:将异常值替换为统计值,如平均值或中位数。
转换:通过数据转换(如对数转换)来减少异常值的影响。
将不同数据类型的数据转换为一致的数据类型,如将字符串转换为数字。
将数据按照一定规则进行格式化,使其更易于处理和分析。
将不同范围的数据转化到相同的范围内,便于比较和分析。常用的归一化方法包括Min-Max归一化和Z-Score归一化。
将来自多个来源的数据组合到单个统一视图中,以提供一致、准确的数据表示。这通常涉及数据转换、聚合和过滤等操作。
将高维数据降到低维,以减少数据量并提高分析效率。常用的降维方法包括主成分分析(PCA)、线性判别分析(LDA)等。
将连续型数据转换为离散型数据,以便于某些特定的数据分析任务,如分类和聚类。
对数据进行平滑处理,以减少噪声和异常值的影响,使数据更易于分析。常用的平滑方法包括移动平均法、指数平滑法等。
分箱法:将需要处理的数据根据一定的规则放进箱子里,然后进行测试和处理。
回归法:利用函数的数据进行绘制图像,然后对图像进行光滑处理,以消除噪声或异常值。
聚类法:将抽象的对象进行集合分组,成为不同的集合,找到在集合意外的孤点(即噪声),然后进行清除。
数据清洗是一个复杂且耗时的过程,需要根据数据的具体情况和业务需求选择合适的清洗方法。同时,数据清洗也是一个反复的过程,需要不断地检查和修正数据中的问题。
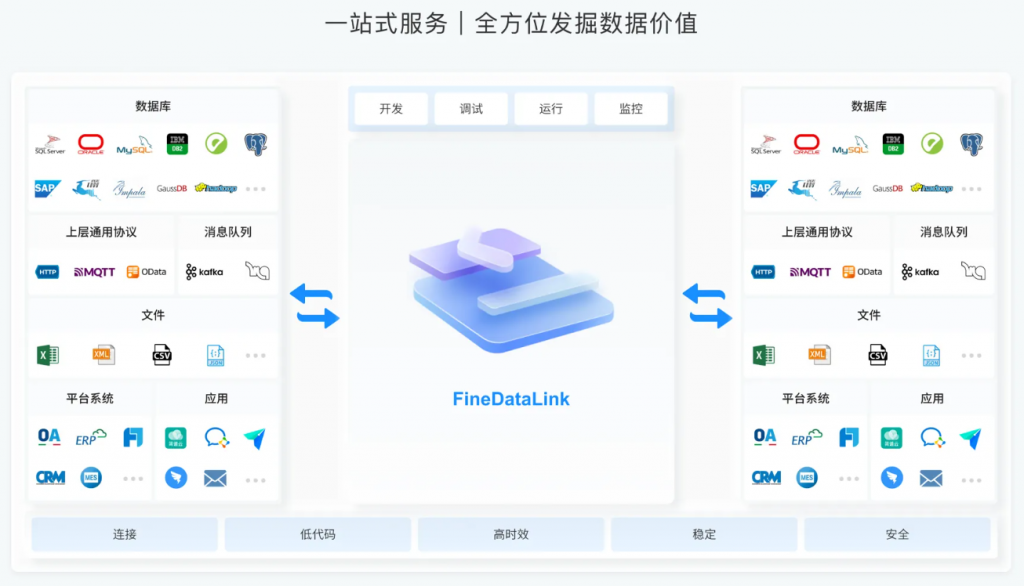
FineDataLink是一款低代码/高时效的数据集成平台,它不仅提供了数据清理和数据分析的功能,还能够将清理后的数据快速应用到其他应用程序中。FineDataLink的功能非常强大,可以轻松地连接多种数据源,包括数据库、文件、云存储等。此外,FineDataLink还支持高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等。使用FineDataLink可以显著提高团队协作效率,减少数据连接和输出的繁琐步骤,使整个数据处理流程更加高效和便捷。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 报表开发有难题?FDL+FR轻松实现业务系统读写分离下一篇: 定时任务自动化导出Excel/CSV,高效归档业务明细数据


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号