作者:finedatalink
发布时间:2024.8.5
阅读次数:199 次浏览
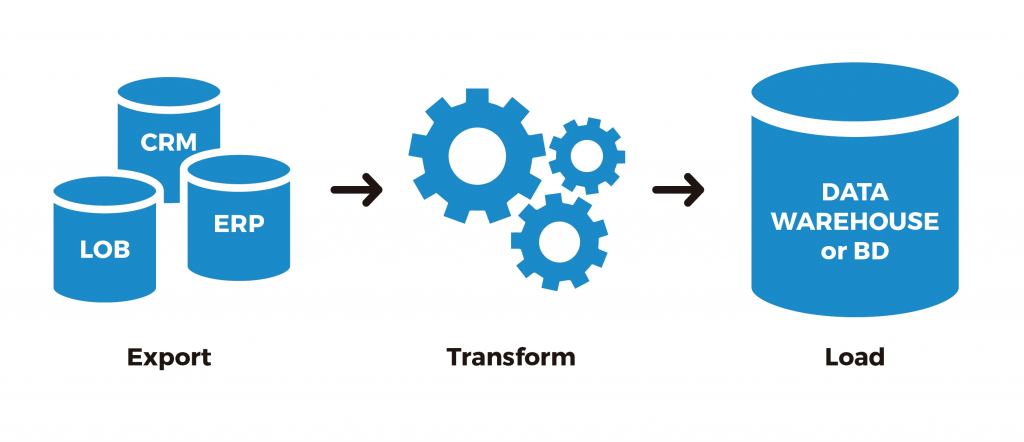
数据管道(Data pipeline)是指一种将数据从一个或多个源头传输、处理和转换至一个或多个目标的自动化过程。数据管道通常用于从不同的数据源(如数据库、文件、API等)中抽取数据,并经过一系列的处理步骤后加载到目标系统(如数据仓库、数据湖等)中。它的主要目的是实现数据的集成、转换和分发,以支持数据驱动的决策和分析。
关键特点和组成部分包括:
1. 数据抽取:从一个或多个数据源中提取数据。这可能涉及到全量抽取或增量抽取,取决于数据源的特性和需求。
2. 数据处理和转换:对抽取的数据进行清洗、转换和加工,使其适合目标系统的要求和格式。
3. 数据加载:将处理后的数据加载到目标系统中,这可能涉及到数据仓库、数据湖、应用程序数据库等。
4. 调度和自动化:数据管道通常是自动化运行的,根据预定的时间表或事件触发器执行数据流动的各个步骤。
5. 监控和错误处理:监控数据流的运行情况,及时发现和处理错误,确保数据的完整性和可靠性。
数据管道的实现可以基于各种技术和工具,如ETL(Extract, Transform, Load)工具、流式计算框架(如Apache Kafka、Apache Flink)、工作流管理系统(如Apache Airflow)等。它们对于现代数据驱动的应用和企业来说是非常重要的,可以帮助实现数据的集成、实时处理和分析,从而支持业务决策和运营优化。
数据管道(Data pipeline)捕获变化数据的方法通常涉及以下步骤和技术:
数据源连接: 首先,数据管道需要连接到数据源,这可以是数据库、日志文件、API 等等。数据管道需要能够访问数据源,并能够从中提取数据。
增量抽取: 数据管道使用增量抽取(Incremental Extraction)的方法捕获变化数据。这意味着它会检测数据源中发生的变化,例如新记录的添加、现有记录的更新或删除。
变化数据检测: 数据管道会记录上次抽取的时间戳或其他标记,以便下次抽取时可以识别自上次抽取以来发生的变化。通过比较当前数据状态和上次抽取的状态,可以检测到哪些数据发生了变化。
增量加载: 捕获到变化数据后,数据管道会将这些变化数据加载到目标系统中,例如数据仓库、数据湖或其他目标数据库中。这个过程通常是增量加载(Incremental Loading),只将新增或变更的数据加载进去,而不是全量替换。
数据同步和转换: 在将数据加载到目标系统之前,有时需要对数据进行转换或同步。这可能包括数据格式转换、字段映射、数据清洗或其他数据处理操作。
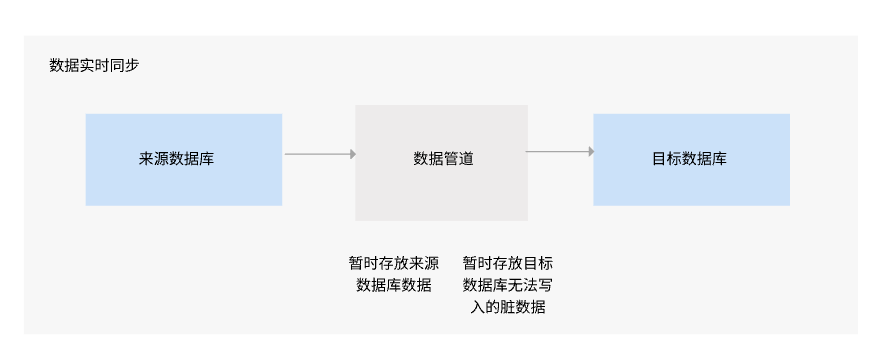
周期性调度: 数据管道通常会设置周期性调度,定期运行增量抽取过程,以确保目标系统中的数据保持最新。调度可以是每天、每小时或根据需要定制的时间间隔。
监控和错误处理: 数据管道还应该具备监控机制,用于检测抽取或加载过程中的错误或异常情况。如果出现错误,需要能够及时通知管理员并进行错误处理,以确保数据的完整性和可靠性。
FineDataLink是帆软软件推出的一站式数据集成平台,低代码/高时效融合多种异构数据,帮助企业解决数据孤岛问题,提升企业数据价值。它通过以下方式实现数据管道:
1. 数据采集:帆软FDL支持多种数据源的采集,包括关系型数据库、非关系型数据库、文件系统、消息队列等。
2. 数据清洗和转换:帆软FDL提供了强大的ETL功能,可以对采集到的数据进行清洗、转换和整合,以满足不同业务需求。
3. 数据同步:帆软FDL支持将处理后的数据同步到目标数据库中,以供业务系统使用。
4. 实时监控和管理:帆软FDL提供了实时监控和管理工具,可以对整个数据管道进行实时监控和管理,以保证系统的稳定性和可靠性。
5. 自动化运维:帆软FDL支持自动化运维功能,可以自动化地完成各种运维任务,如备份、恢复、升级等。
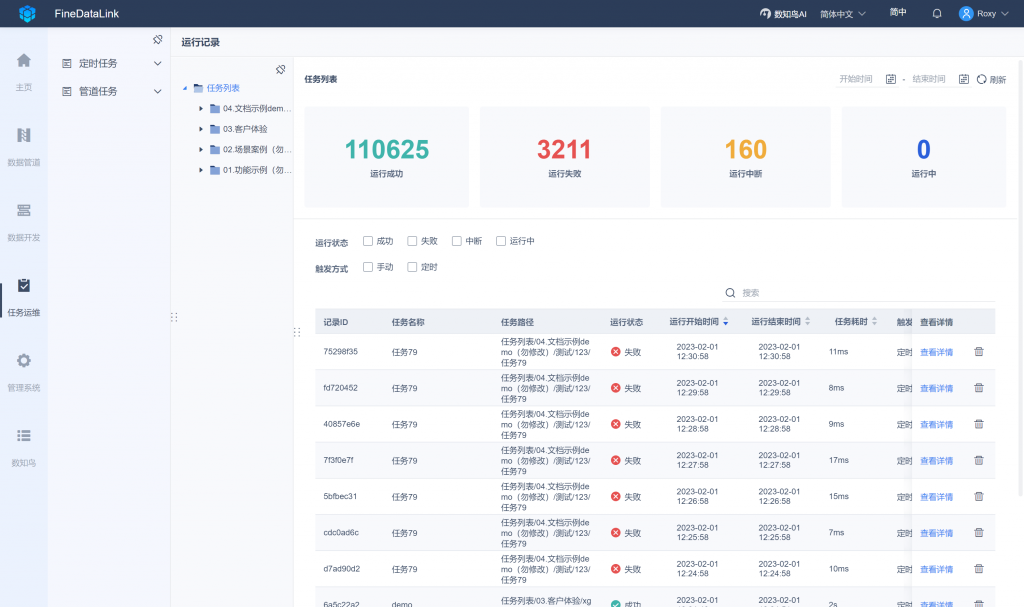
总之,帆软FDL通过提供全面的功能和易用性来实现数据管道。它可以帮助企业快速构建高效稳定的数据处理流程,并提高数据处理效率和质量。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 什么是ETL增量抽取?终于有人讲明白了下一篇: OLAP技术与数据仓库:深度分析与决策支持


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号