作者:finedatalink
发布时间:2024.8.23
阅读次数:235 次浏览
随着大数据时代的到来,企业对数据的实时性、准确性和可用性的要求越来越高。但在现实操作中,传统数据同步技术常常难以满足这些需求,在处理日益增长的数据量和实时性需求方面显得力不从心。企业在数据同步和管理过程中遇到的问题和痛点,不仅影响了决策的时效性,也对业务的连续性和稳定性构成了挑战。
在大型购物节如双十一和618期间,电商平台会推出众多促销活动,吸引大量消费者参与购买。这导致支付和退款问题激增,并通过微信、云闪付APP、电话等渠道反馈至客服中心,产生海量数据。企业需要实时同步这些数据至数据大屏,以实时展示支付和消费动态,并实现风险自动预警。
传统的解决方案有两种:
一是提高定时ETL任务的执行频率,以达到数据的及时处理;
二是业务系统提供的数据变更时的消息通知接口,企业IT人员编写代码来实现监控,基于监控调起数据处理任务运行。
但这些方案都存在很大的问题,首先,定时任务执行频率过高,会导致系统性能负担急剧增加,很容易造成卡顿甚至宕机。其次,编程实现数据监控,技术上要求较高,还会会带来任务运维的复杂性。企业需要一个能够自动监听数据变更,让数据处理类任务及时完成计算,以保证目标库中数据的实时性的工具。
很多业务人员会使用FineReport进行数据可视化和报表开发。通常情况下,业务人员会用报表工具直接连接业务系统数据库,在报表内的sql数据集进行数据清洗和加工,或者在报表单元格内写过滤条件实现跨库数据关联。这样做非常方便快捷,给业务人员节省了很多时间,但是长期使用报表工具直连业务库的形式,很容易造成性能问题,由于报表工具直连数据库,数据的读取请求完全依赖于业务库,当数据量增大、计算逻辑变得复杂时,业务系统和报表前端都会面临很大性能压力。遇到数据录入的高发期,系统的高负荷运转会造成严重的卡顿,甚至出现宕机的风险,大大影响工作效率。
企业在构建ODS层或者进行其他原表同步的场景下,由于数据量比较大,直接做大数据量的查询与更新会有比较严重的性能消耗,传统的解决办法是定时查询数据做同步,用时间戳等作为标识,增量更新数据。但是很多情况下,企业的业务库表结构不规范,可能缺少主键、时间戳,不能很好地通过时间戳或者主键比较实现数据更新。但是如果用全清全写的方式,数据同步耗时会比较长,并且会导致一段时间的目标库不可用。企业期望用监控源表数据变化的形式,实时地流式增量更新数据。
数据流任务在执行时,遇到网络中断、源表结构变化等异常情况时会被中断。在数据流执行失败后,企业IT人员只能人工去排查出错点,清理存在问题的数据,这一过程不仅耗时耗力,还会严重影响数据同步效率。企业希望数据流任务执行失败后,对目标库进行数据回滚,删除已经写入目标库的内容。
综上所述,传统数据同步技术在满足现代企业对数据实时性、高效性和稳定性的需求方面存在明显不足。企业亟需一种新的数据同步解决方案,能够自动监听数据变更,实现实时、增量的数据同步,并具备强大的容错和回滚能力,以确保数据的连续性、一致性和可用性。针对上述问题,FineDataLink为企业客户提供了全面的解决方案。
FDL 通过日志解析技术,通过LogMiner、binlog、CDC等日志解析的方式,实时获取数据行的增加、修改和删除情况,将数据的变化情况暂存到 kafka 消息队列,再由数据目标端完成数据覆盖,进而完成了数据实时同步,减轻数据同步对源库带来的数据压力。实现从多个业务数据库,实时捕获源数据库的变化,并毫秒内更新到目的数据库。
构建企业级数据中心或数据仓库,原始数据层也就是我们常说的 ods 层,包括的数据表会非常多,传统数据处理工具只能每张数据表创建 1 个任务,这种方式的工作量会非常大,操作过程很繁琐。针对这一问题,FDL 提供了多表批量同步,我们可以一次性勾选多张数据表,管道任务开始运行后,这些数据表会一并写入到目标端。
同时FDL数据管道的来源和目标是解耦的,不同类型数据库之间也可以进行数据传输。
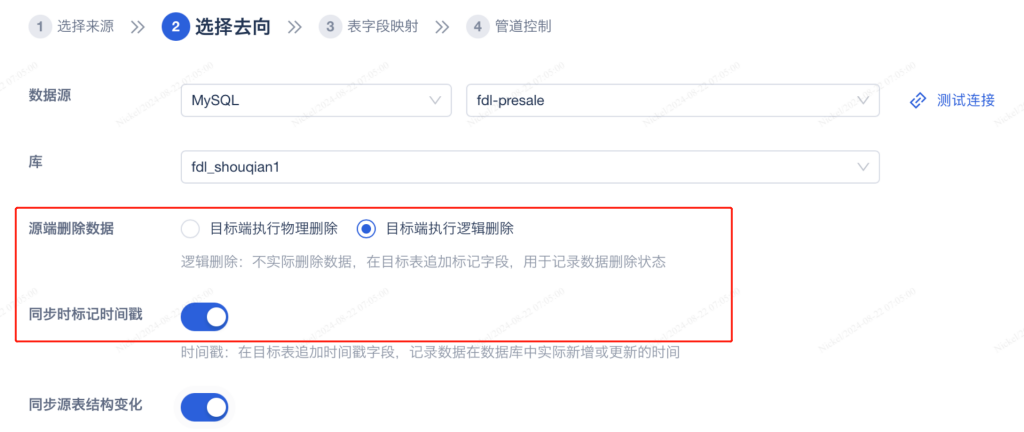
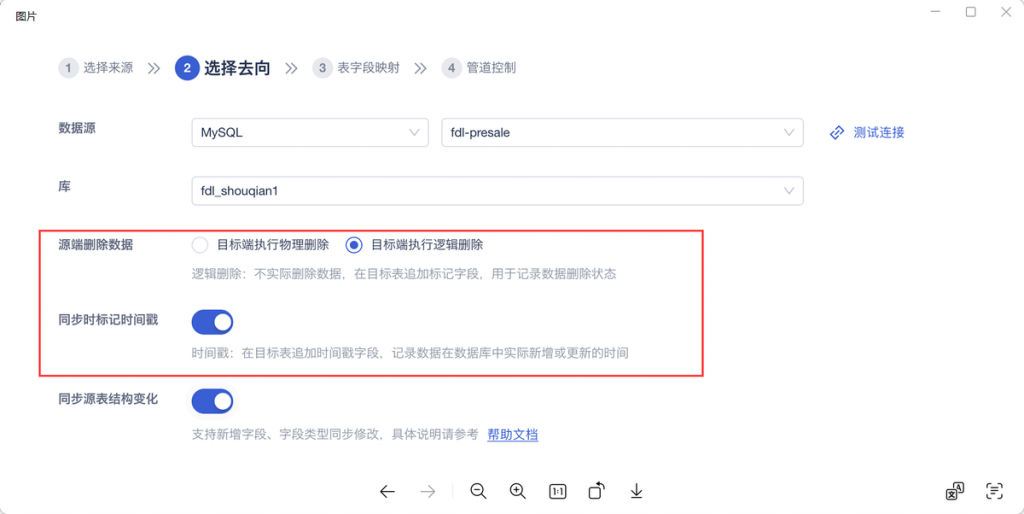
目标表逻辑删除,企业级数据中心会有一个核心思想,数据只增不删,也就是来源表的数据进行了删除,目标表的数据不进行真正物理删除,而是通过增加一个“逻辑删除位”字段的方式来对数据是否有效进行标识。
比如:来源表的某一行数据被删除了,目标表的对应数据的逻辑删除位字段标记此行数据失效即可。这个功能解决的业务场景是业务人员对历史的回溯查看,来达到数据备份、历史数据恢复的效果。
信息系统年久失修,比较多的数据表都是没有数据更新时间戳的,所以我们无从了解数据的创建时间和更新时间,数据管道支持在同步来源数据时,在目标表中自动给数据加上数据更新时间戳,每条数据有了生命后,我们可以在后续流程中进行数据增量同步、增量计算,进而提升数据全链路的时效性。
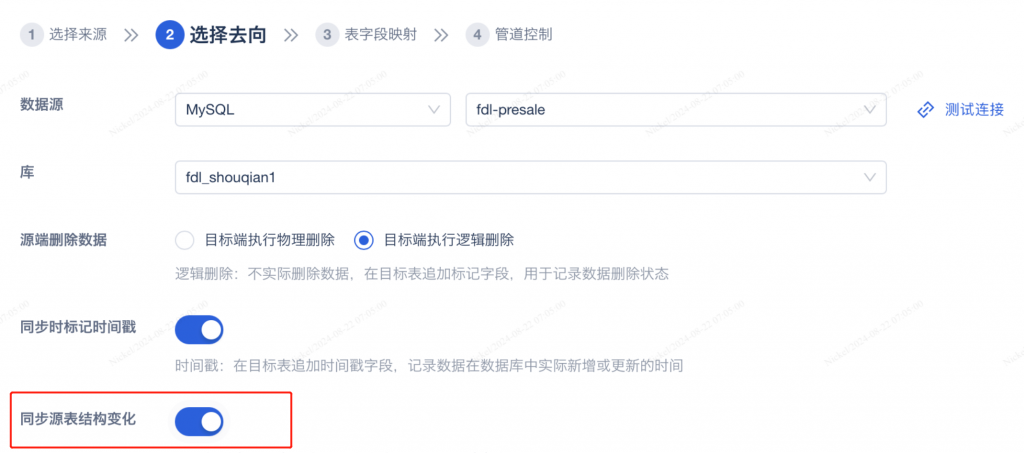
来源表的结构变化,比如:字段的新增、修改和删除,数据管道可以自动识别,将字段的变化情况覆盖到目标表中。业务系统的调整会导致来源表字段变化,传统数据处理工具的方案中,目标表需要IT 人员手动调整,费时费力,FDL 的自动化方案可以大幅节省后续运维工作。
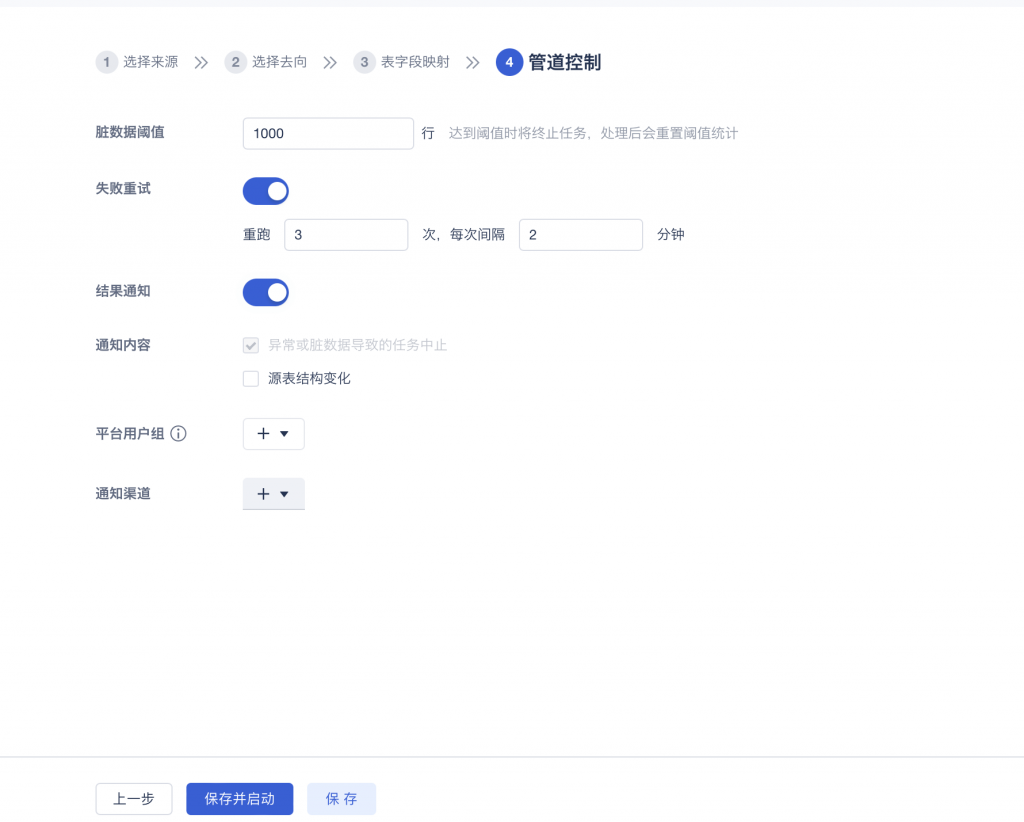
脏数据阈值:当来源表数据无法写入目标表字段时,比如;字段的长度和格式不匹配,会被数据管道定义为脏数据,管道支持脏数据的阈值手动调整。
失败重试:管道任务运行起来后,会存在由于数据来源端服务器或数据库不稳定情况导致的临时性运行失败,失败重试可以让任务自动重新执行,为运维人员节省了不必要的运维工作。
消息通知:当任务的脏数据达到阈值时,管道任务确实报错了,此时可以通过多个通知渠道,将失败信息提醒到运维人员,已经支持企业微信、钉钉、飞书等多个渠道。
FineDataLink,它小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,应有尽有,功能很强大。最重要的是,因为这个工具,整个公司的数据架构都可以变得规范。而且它是java编写的,类流程图式的ETL开发模式,上手都很简单:数据对接、任务复用简直都是小case,大大降低了数据开发的门槛。在企业中被关注最多的任务运维,FineDataLink大运维平台,支持文件夹式开发模式,报错任务可一键直达修改,报错优化清晰易懂;通过权限控制,保障系统安全。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号