作者:finedatalink
发布时间:2024.7.30
阅读次数:123 次浏览
数据实时同步的实现是一个复杂但关键的过程,它对于确保数据的一致性、高可用性和实时性至关重要。以下是一些实现数据实时同步的常用方法和步骤:
1.原理:主数据库(Master)负责处理所有的写操作,并将这些操作的变更记录(如二进制日志)实时发送给从数据库(Slave)。从数据库则负责读取这些变更记录,并应用到自身数据库上,从而实现数据的实时同步。
2.优点:可以实现高可用性和负载均衡,支持异地备份。
3.实施步骤:配置主数据库以记录二进制日志。
配置从数据库以连接到主数据库,并请求二进制日志。
从数据库读取并应用这些日志中的变更,以保持与主数据库的数据一致。
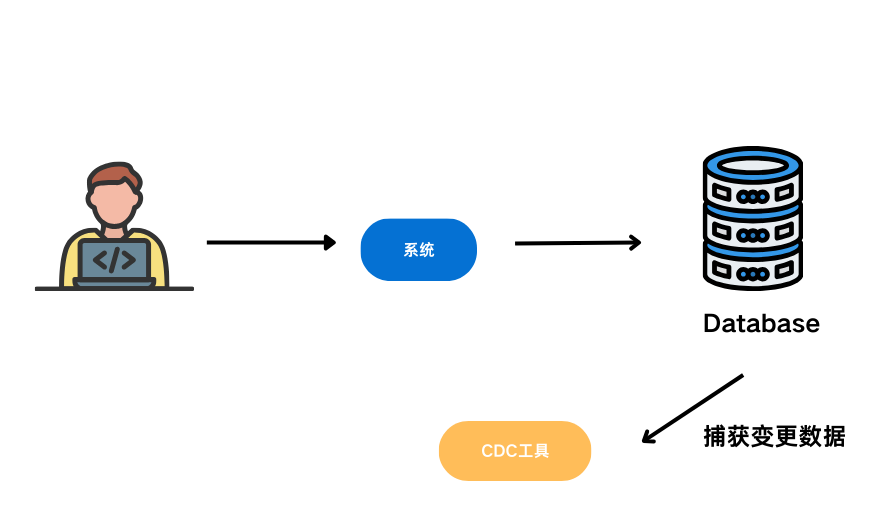
1.原理:通过解析数据库的事务日志(如Oracle的Redo日志、MySQL的Binary Log)来捕获数据的变更(包括插入、更新、删除操作)。
2.优点:实时性高、无侵入性,能捕获所有变更。
3.实施步骤:开启数据库的日志记录功能。
使用CDC工具(如Oracle的LogMiner、开源的Debezium等)解析日志。
将捕获的变更数据实时传输到目标数据库或数据仓库。
1.原理:通过定期比较源数据库和目标数据库的快照来检测数据变更。
2.优点:能够捕获所有变更,但实时性较低。
3.实施步骤:在源数据库和目标数据库上定期创建快照。
比较两个快照之间的差异,确定数据变更。
将变更数据应用到目标数据库。
1.原理:将数据变更以消息的形式发送到消息队列(如Apache Kafka),然后使用流处理引擎(如Apache Flink)对这些消息进行实时处理和分析,最后将处理结果写入目标数据库。
2.优点:高吞吐量、低延迟,支持复杂的数据处理逻辑。
3.实施步骤:配置数据源以将变更数据发送到消息队列。
使用流处理引擎订阅消息队列,并编写处理逻辑。
将处理结果写入目标数据库。
工具介绍:如Oracle GoldenGate、Attunity Replicate、FineDataLink等,这些工具提供了强大的数据同步功能,支持各种数据库平台,并提供了用户友好的界面和灵活的同步规则配置。
FineDataLink:是帆软开发的一款实时数据同步工具,支持多种数据库类型。
FineDataLink作为一款实时数据同步工具,具有以下几个优势:
1.集成度高:FineDataLink与FineReport BI工具集成紧密,可以直接在FineReport界面中进行数据同步的配置和监控。
2.多种数据源支持:FineDataLink支持多种数据库类型,包括Oracle、MySQL、SQL Server等。
3.多种同步方式支持:FineDataLink支持全量同步、增量同步和定时同步等多种同步方式,可以根据具体需求进行选择。
4.高效稳定:FineDataLink采用高效稳定的数据同步引擎,可以实现异构数据库之间的实时同步,并支持大规模数据量的同步操作。
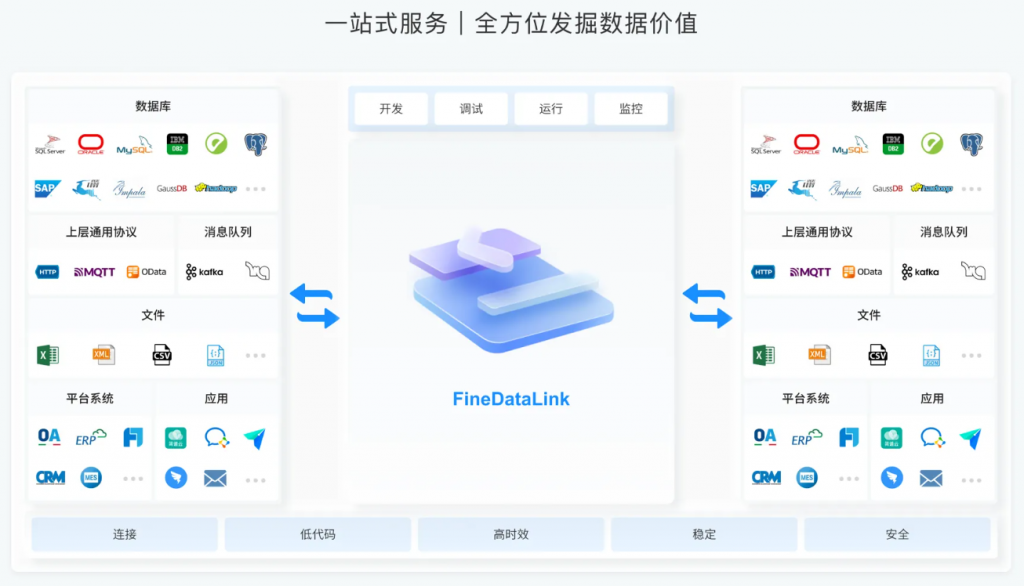
FineDataLink——中国领先的低代码/高时效数据集成工具,能够为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号