作者:finedatalink
发布时间:2024.7.30
阅读次数:89 次浏览
数据清洗是在数据处理和分析之前,对数据集进行清理和整理的过程。这个过程包括识别并纠正错误的、不完整的、不准确的、不相关的或者是重复的数据,以确保数据的质量和准确性。数据清洗的目的是提高数据的质量,使其更适合进行数据分析或数据挖掘。
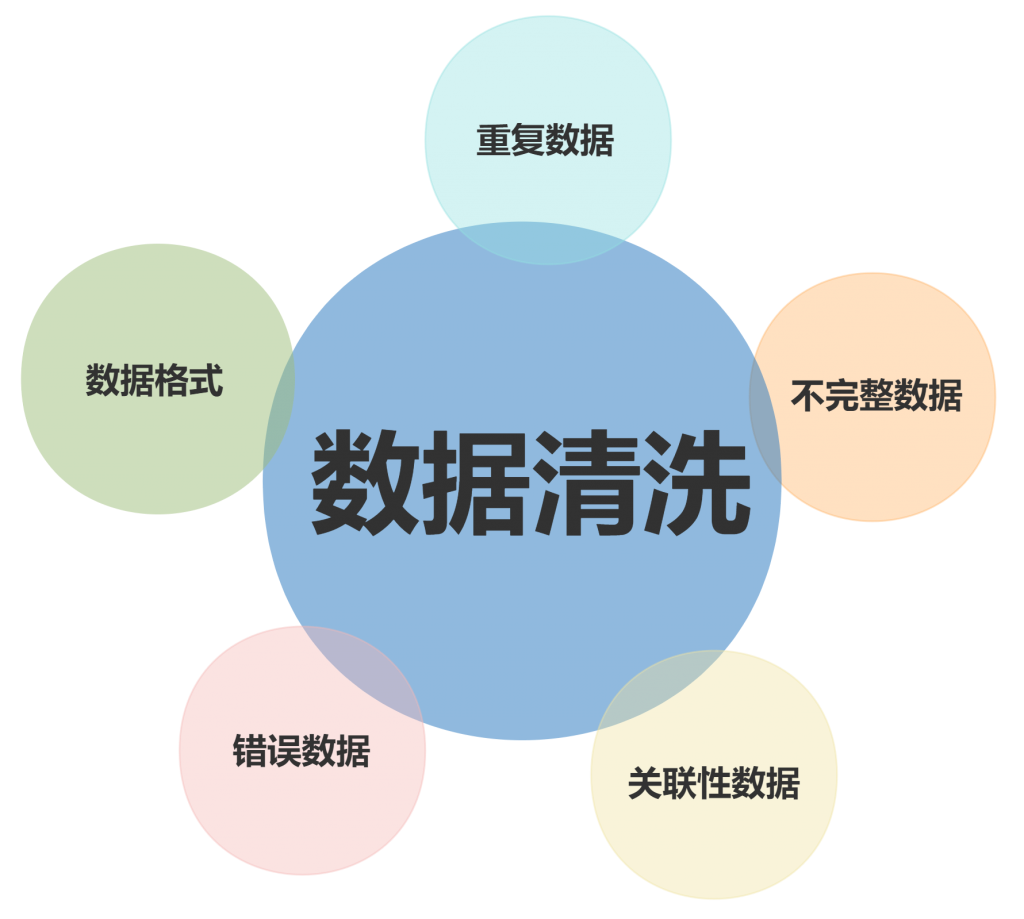
数据可能存在错误、缺失值、格式不一致等问题,这些都需要通过数据清洗来解决。
随着数据量的增加,手动进行数据清洗变得越来越不现实,需要依赖自动化工具来提高效率。
数据可能来自不同的来源,每个来源的数据格式和质量都可能不同,需要统一处理以保证数据的一致性。
数据清洗是一个耗时的过程,尤其是在数据量大和数据质量差的情况下,需要投入大量的时间和资源。
通过使用专业的数据处理工具,如FineDataLink,可以有效地解决数据清洗的痛点,提高数据处理的效率和质量。FineDataLink提供了多种可视化算子和功能,如新增计算列、数据过滤、数据关联等,帮助用户快速完成数据清洗和处理,无需编写复杂的SQL语句,大大提升了开发效率。
当用户需要进行空值、重复值过滤,或是筛选出符合目标的值以进一步处理时,可以直接使用「数据转换」中的数据过滤功能进行数据处理。这是数据清洗中非常基础且常用的功能,有助于提高数据的质量和可用性。
FDL提供了「新增计算列」功能,可以使用多种函数实现对数据的清洗计算。这个功能允许用户对数据进行各种计算操作,如字符串处理、数值计算等,非常适合对数据进行预处理和转换。
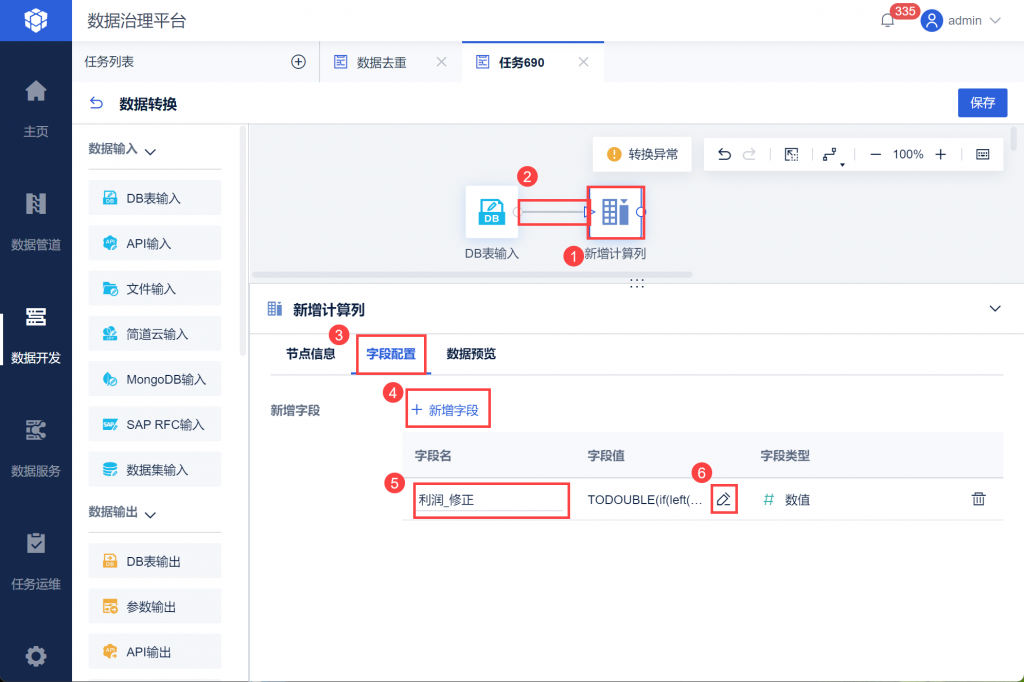
「数据关联」功能可以帮助用户将不同数据源中的数据进行关联,这在清洗数据时尤其有用,比如需要合并来自不同源的数据并进行一致性校验。
「列转行」和「行转列」功能可以帮助用户调整数据的结构,使其更适合后续的分析和处理。这对于数据清洗和准备阶段来说是非常重要的,可以帮助用户解决数据结构不一致的问题。
对于可视化算子不够丰富的情况,用户可以使用「Spark SQL」语法进行数据快速处理。这为数据清洗提供了极大的灵活性,用户可以编写SQL语句来执行复杂的数据清洗任务。
通过这些功能,FineDataLink为用户提供了强大的数据清洗能力,帮助用户提高数据质量,为数据分析和业务决策提供可靠的数据支持。
FineDataLink是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业快速构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。同时,帆软FDL也支持开放API和服务接口,可以对接其他接口数据,与其他数据工具和系统进行整合和拓展。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 为什么要读写分离?如何实现业务系统读写分离?下一篇: 值得收藏!五个好用的数据清洗工具推荐


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号