作者:finedatalink
发布时间:2024.8.1
阅读次数:127 次浏览
在数字化转型的浪潮中,企业对于数据处理的实时性和高效性需求日益增长,推动了从传统数据处理架构向实时数仓的演进。这一转型不仅要求技术上的革新,更涉及企业数据战略、组织架构、流程优化等多个层面的深刻变革。然而,在这一过程中,企业往往面临着诸多挑战与潜在陷阱,如技术选型不当、数据治理缺失、性能瓶颈等。因此,如何科学规划、稳步实施并有效避免转型过程中的“坑”,成为企业成功迈向实时数仓时代的关键。
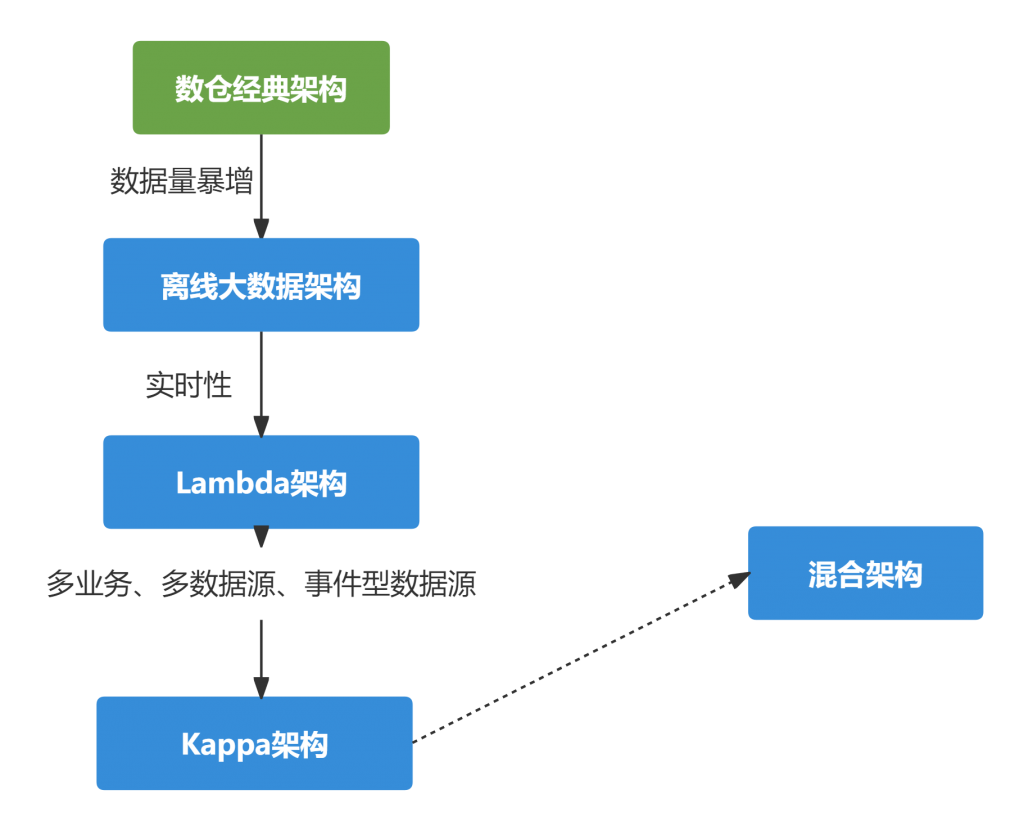
从1990年 Inmon 提出数据仓库概念到今天,数仓架构经历了最初的传统数仓架构、离线大数据架构、Lambda 架构、Kappa 架构以及由Flink 的火热带出的流批一体架构,数据架构技术不断演进,本质是在往流批一体的方向发展,让用户能以最自然、最小的成本完成实时计算。
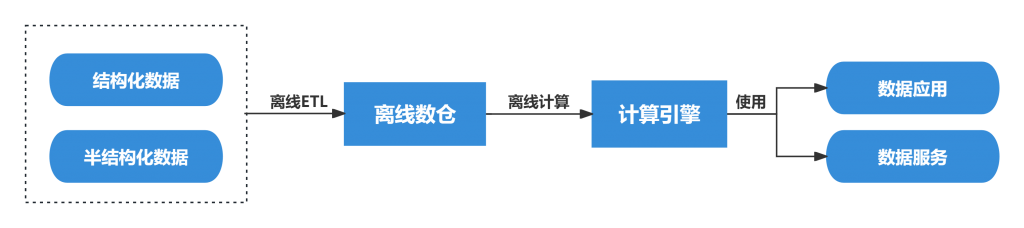
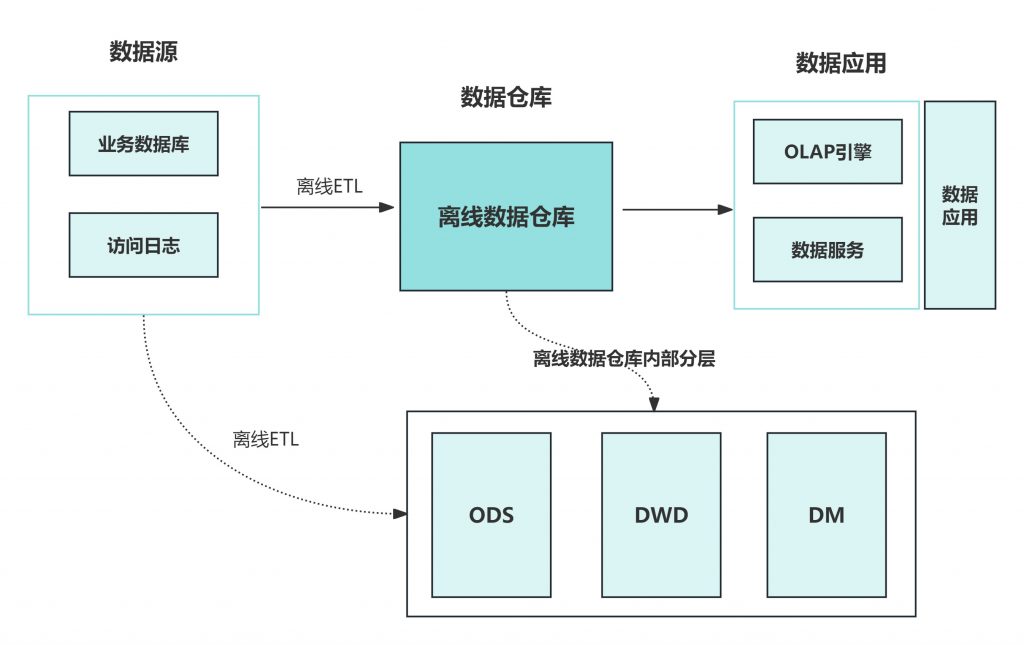
这是比较传统的一种方式,结构或半结构化数据通过离线ETL定期加载到离线数仓,之后通过计算引擎取得结果,供前端使用。这里的离线数仓+计算引擎,通常是使用大型商业数据库来承担,例如Oracle、DB2、Teradata等。
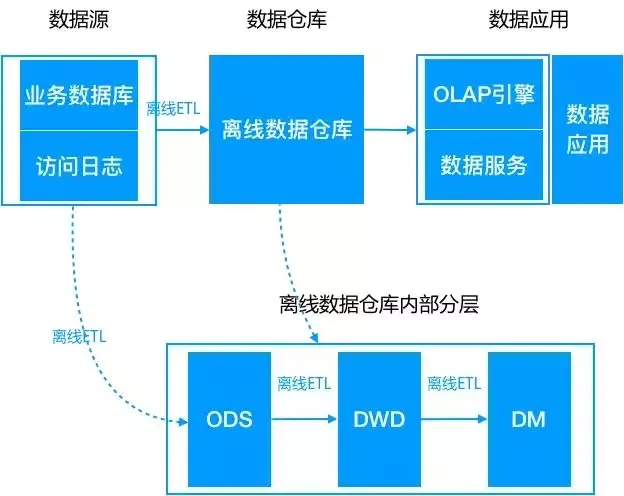
随着数据规模的不断增大,传统数仓方式难以承载海量数据。随着大数据技术的普及,采用大数据技术来承载存储与计算任务。数据源通过离线的方式导入到离线数仓中。下游应用根据业务需求选择直接读取 DM 或加一层数据服务,比如 MySQL 或 Redis。
数据仓库从模型层面分为三层:
当然,也可以使用传传统数据库集群或MPP架构数据库来完成。例如Hadoop+Hive/Spark、Oracle RAC、GreenPlum等。
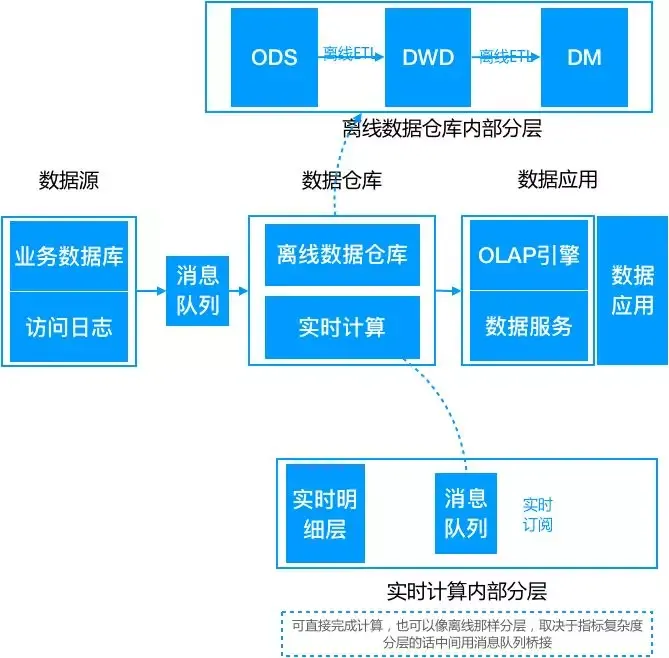
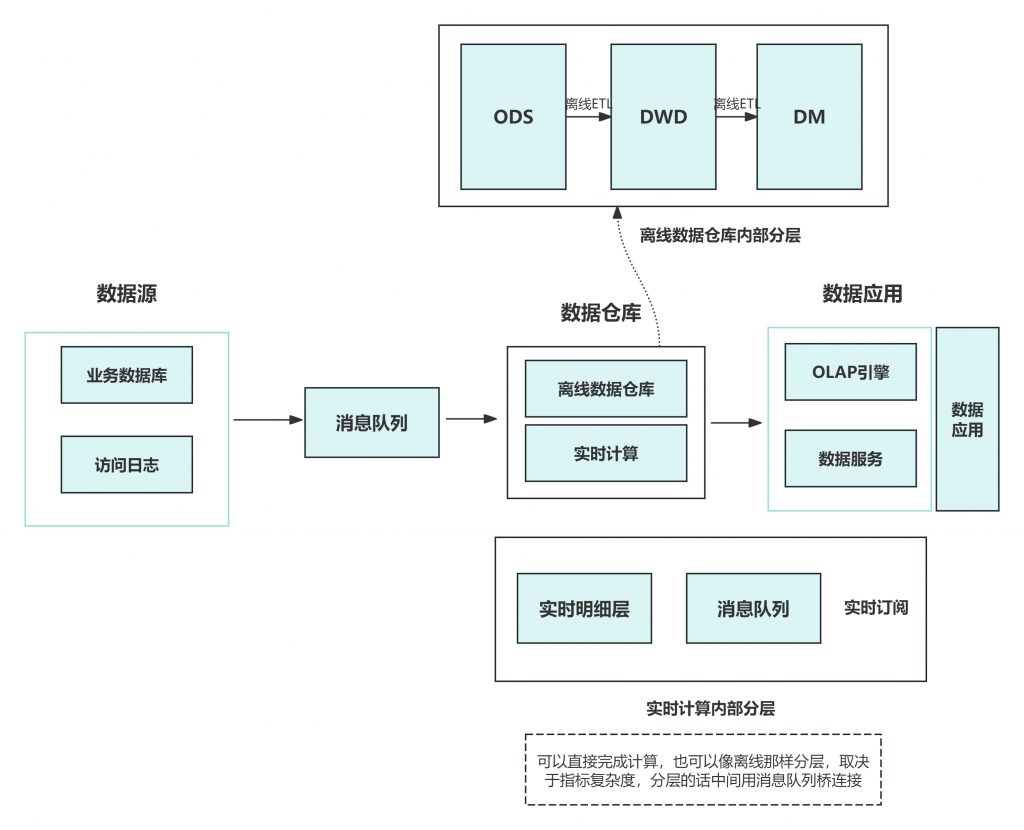
随着业务的发展,随着业务的发展,人们对数据实时性提出了更高的要求。此时,出现了Lambda架构,其将对实时性要求高的部分拆分出来,增加条实时计算链路。从源头开始做流式改造,将数据发送到消息队列中,实时计算引擎消费队列数据,完成实时数据的增量计算。与此同时,批量处理部分依然存在,实时与批量并行运行。最终由统一的数据服务层合并结果给于前端。一般是以批量处理结果为准,实时结果主要为快速响应。
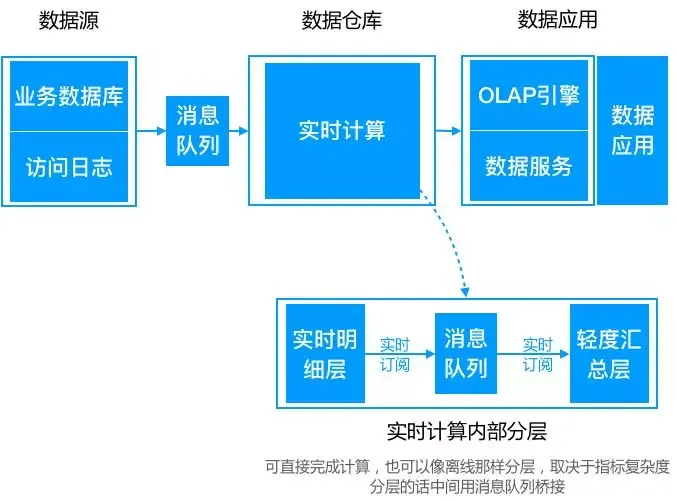
而Lambda架构,一个比较严重的问题就是需要维护两套逻辑。一部分在批量引擎实现,一部分在流式引擎实现,维护成本很高。此外,对资源消耗也较大。随后诞生的Kappa架构,正是为了解决上述问题。其在数据需要重新处理或数据变更时,可通过历史数据重新处理来完成。方式是通过上游重放完成(从数据源拉取数据重新计算)。
可Kappa架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。
上述架构各有其适应场景,有时需要综合使用上述架构组合满足实际需求。当然这也必将带来架构的复杂度。用户应根据自身需求,有所取舍。在一般大多数场景下,是可以使用单一架构解决问题。现在很多产品在流批一体、海量、实时性方面也有非常好的表现,可以考虑这种“全能手”解决问题。
数据源通过离线的方式导入到离线数据中。下游应用根据业务需求选择直接读取 DM 或加一层数据服务,比如 MySQL 或 Redis。数据仓库从模型层面分为三层:
ODS,操作数据层,保存原始数据;
DWD,数据仓库明细层,根据主题定义好事实与维度表,保存最细粒度的事实数据;
DM,数据集市/轻度汇总层,在 DWD 层的基础之上根据不同的业务需求做轻度汇总;
典型的数仓存储是 HDFS/Hive,ETL 可以是 MapReduce 脚本或 HiveSQL。
Lambda 架构问题:
同样的需求需要开发两套一样的代码:这是 Lambda 架构最大的问题,两套代码不仅仅意味着开发困难(同样的需求,一个在批处理引擎上实现,一个在流处理引擎上实现,还要分别构造数据测试保证两者结果一致),后期维护更加困难,比如需求变更后需要分别更改两套代码,独立测试结果,且两个作业需要同步上线。
资源占用增多:同样的逻辑计算两次,整体资源占用会增多,多出实时计算这部分
Lambda 架构虽然满足了实时的需求,但带来了更多的开发与运维工作,其架构背景是流处理引擎还不完善,流处理的结果只作为临时的、近似的值提供参考。后来随着 Flink 等流处理引擎的出现,流处理技术很成熟了,这时为了解决两套代码的问题,LickedIn 的 Jay Kreps 提出了 Kappa 架构。
Kappa 架构可以认为是 Lambda 架构的简化版(只要移除 lambda 架构中的批处理部分即可)。
在 Kappa 架构中,需求修改或历史数据重新处理都通过上游重放完成。
Kappa 架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。
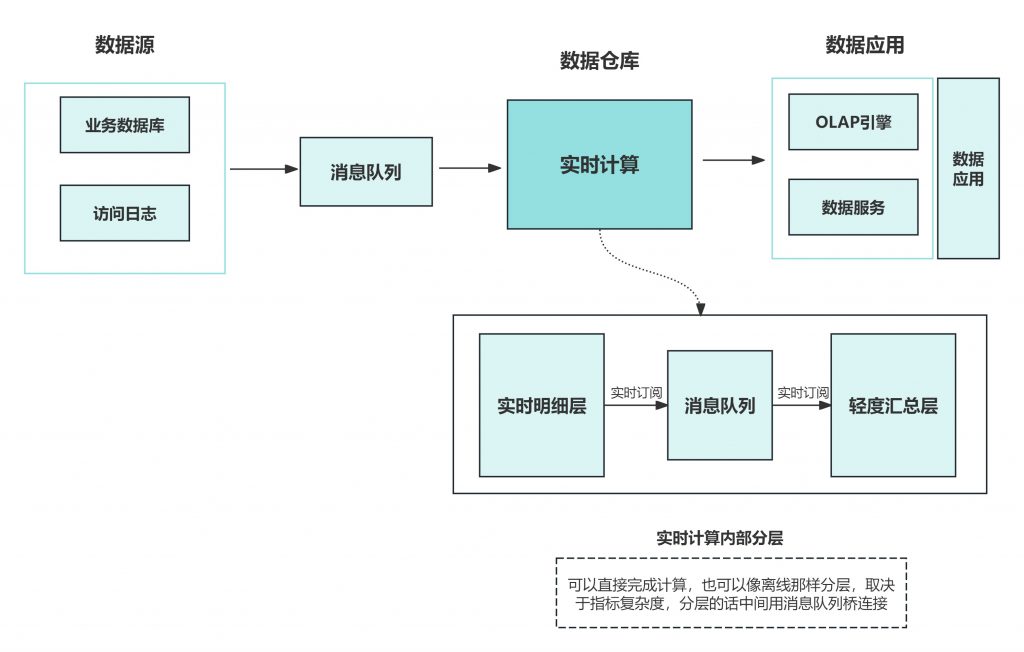
构建实时数仓需要根据业务需求选择合适的技术架构,并通过ETL工具来实现数据的实时采集、处理和分析,最终将结果存储到实时数据仓库中,并进行数据可视化和应用开发。
帆软软件推出的FineDataLink提供了一套完整而灵活的解决方案,可以帮助用户快速构建可靠的高时效/近实时数据仓库系统。在构建高时效/近实时数据仓库时,帆软FDL有以下优势:
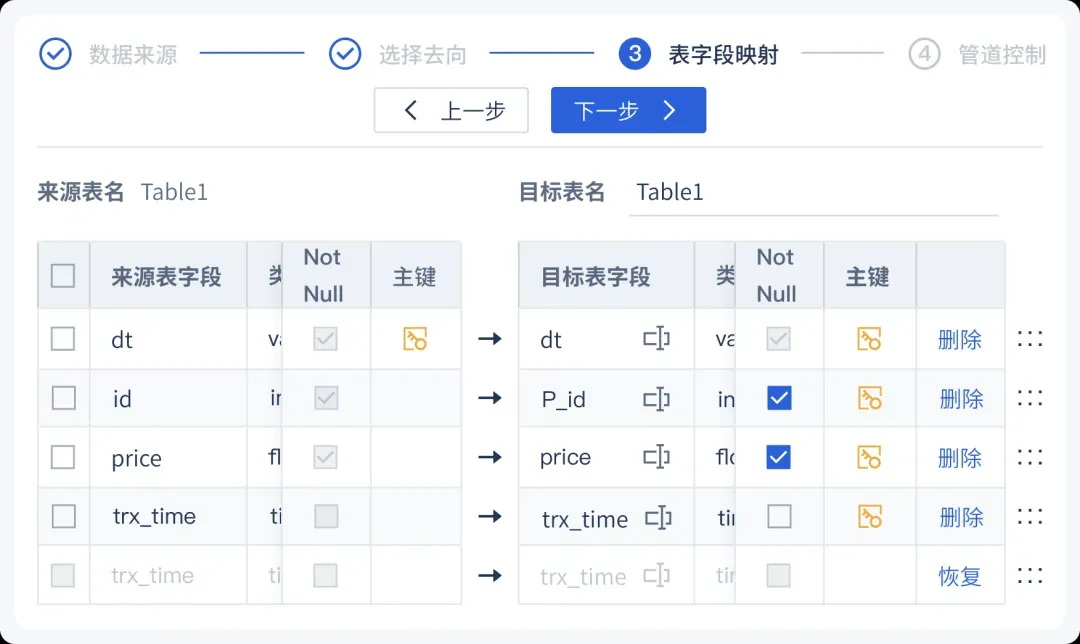
1. 操作界面简洁清晰,无代码配置,字段自动映射,无需专业的编程能力即可完成任务配置。
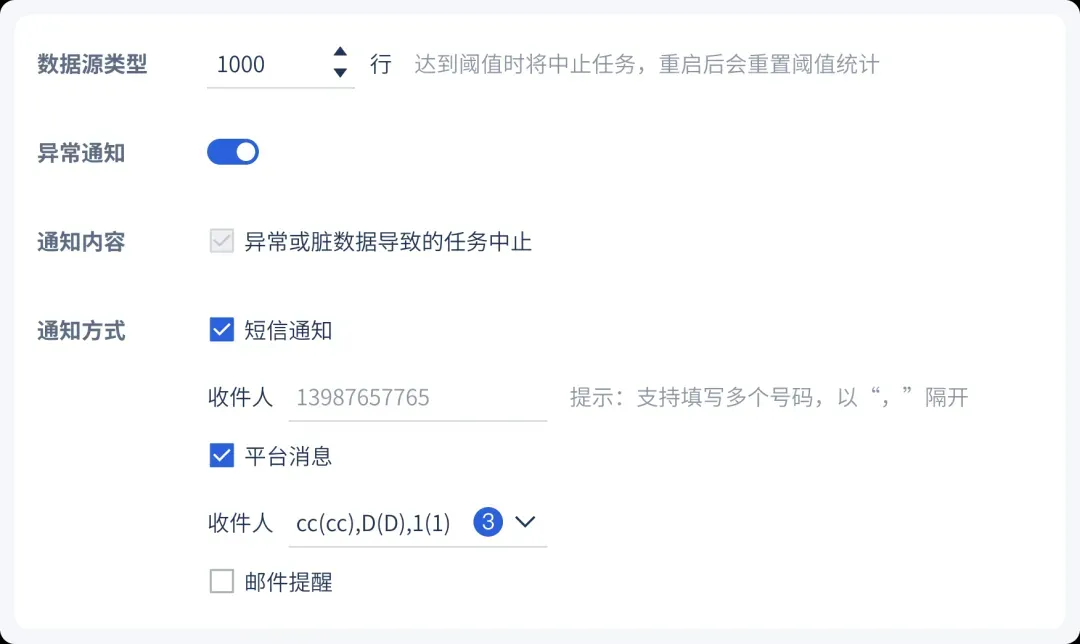
2. 提供统一的错误队列管理、预警机制、日志管理,支持脏数据阈值设置和通知功能,可通过短信、邮件、平台消息等进行消息提醒,保证企业敏感数据的安全性。
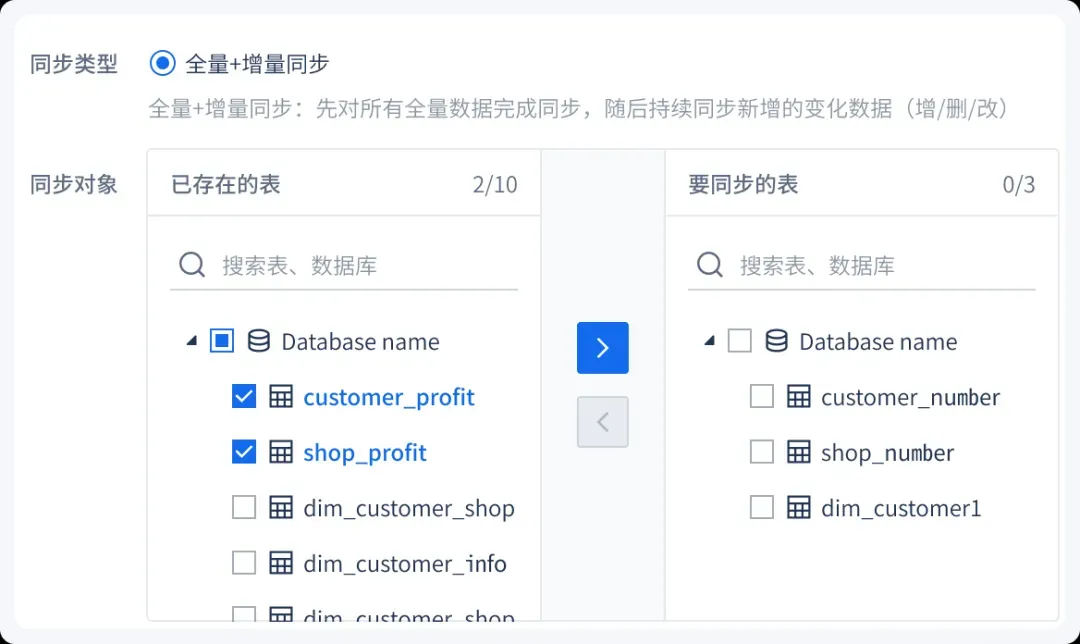
3. 打破数据壁垒,实现低成本业务系统的数据实时同步,从多个业务数据库实时捕获源数据库的变化并毫秒内更新到目的数据库。
综上所述,数仓建设是企业数据管理和决策支持的关键环节,在实践中,企业需要根据自身业务需求和数据规模,选择合适的数仓建设方案和技术方案,以提高企业数据资产的价值和利用效率。
FineDataLink——小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,另外它可以满足数据实时同步的场景,应有尽有,功能很强大。如果您需要进行实时数仓建设,帆软FDL会是您的最优解。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 数据同步的实时性无法满足怎么办?实时ODS层数仓搭建更具时效性!下一篇: 值得收藏!一文详解分析型数据库发展历程


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号