作者:finedatalink
发布时间:2023.7.26
阅读次数:414 次浏览
多源异构数据的数据来源非常广泛,可能来自于不同的数据库系统、不同的设备、不同的业务系统、不同的数据格式等。由于这些数据源的差异,造成了数据格式、数据类型、数据来源和数据访问方式等方面的异构性。

多源异构数据通常可以分为以下三种类型:
1. 结构化数据:以关系模式为基础,能够通过关系型数据库进行存储与存取,并具有特定的格式与结构的数据。
2. 半结构化数据:没有遵从关系模式,但是拥有某些基础架构,例如XML、JSON格式的文档、日志文件等。
3. 非结构化数据则:没有明显的结构模式和格式限制的数据,例如Word、PDF、PPT、EXCEL、图像、视频等。
由于不同类型的数据在形成过程中缺乏统一的标准,数据的标签、格式、内容等方面的差异非常大,因此形成了数据的“异构”特征。针对这种异构性,需要选择合适的方法和ETL工具进行数据集成、清洗、处理和分析,以确保数据的质量和价值。

对于多源结构化数据融合,数据的ETL处理和时效性是重点。要确保数据处理和转换的正确性和时效性,需要关注以下几个方面:
1. 数据映射:由于表结构不同,需要进行字段映射,确保数据在不同的表中可以正确地映射和匹配。
2. 列操作:若要新增表字段,需要使用列操作来添加新列。这要求ETL工具可以从源表和目标表中读取元数据,根据元数据生成动态的ETL代码。
3. 字段转换:如果需要对表字段进行二次处理规范,需要支持字段转换功能,比如支持公式或其他自定义操作。这需要ETL工具可以提供灵活的数据转换和处理功能。
4. 范式要求:在设计新增表时,需要保证三大范式。这需要在ETL处理的过程中,对数据进行规整和调整,确保数据符合范式要求。
5. 数据同步时效性:在数据同步时,需要根据业务需求来确定同步的频率和时效性,例如半小时一次、一天一次或实时同步等。
对于半结构化和非结构化数据,由于数据的分散性和复杂性,数据的管理和利用确实面临着一定的挑战。
针对这种情况,可以利用技术对海量和分散的数据进行汇总、聚合和分析,从而挖掘出数据的潜在价值。同时,也需要合理地进行数据分类和标准化,便于统一的管理和利用。

通常处理半结构化和非结构化数据的方法如下:
1. 从半结构化、非结构化数据中提取关键信息,并将其转换为结构化数据。此方法可以将海量、分散的半结构化、非结构化数据转化为结构化数据,并批量进行各种数据分析,发掘数据价值,有效地提高数据利用价值。
2. 通过自定义规则,从大量的半结构化与非结构化数据中,挖掘出其中的关键性信息。此方法需要运用多种文本挖掘工具和自然语言处理技术,通过自学习算法和正则表达式,挖掘出文本中的数据价值。
这两种方法对半结构化和非结构化数据的处理都有自己的优势和缺点,需要根据具体的业务场景和需求来选择合适的方法。
另外,在处理历史数据备份的过程中,可以使用FTP或SFTP等工具进行文件备份和存储,同时还需要对文件进行业务分类、命名、路径管理等,方便数据的查找和访问。同时,还需要使用权限管理来保护数据的安全性和机密性,确保数据备份的可靠性和完整性。
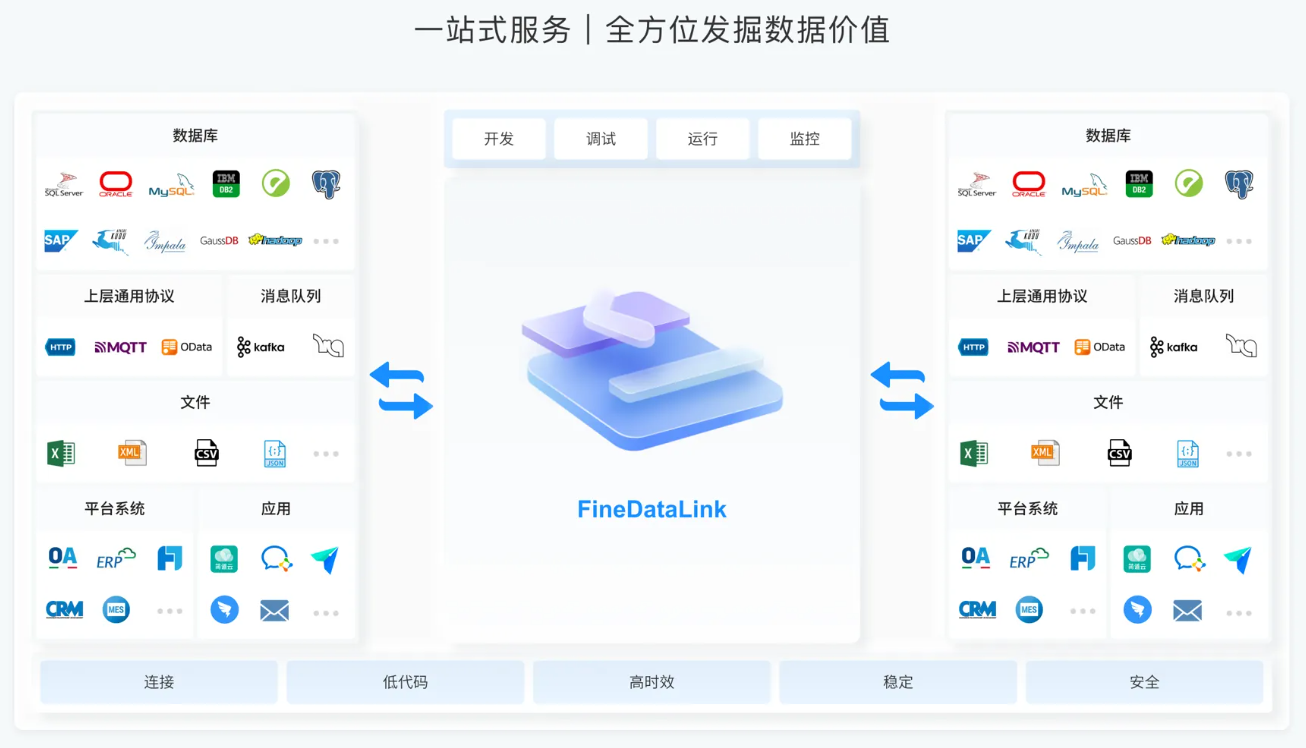
FineDataLink是一款自助式数据治理工具,提供了强大的异构数据源处理技术,可以显着降低开发人员、数据分析师和研究人员的工作量,提高数据处理的效率和准确性,帮助企业更好地管理和分析数据。
相关文章:

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 关于数据仓库治理,你想知道的都在这里下一篇: 扫盲系列(1):数据仓库之基本概述


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号