

 帮助文档
帮助文档 学习视频
学习视频
总而言之,在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。

作者:finedatalink
发布时间:2023.7.28
阅读次数:6,512 次浏览
针对这种的话,会综合考虑数据价值和投入产出比,因为这部分的数据处理较为复杂。
FineDataLink
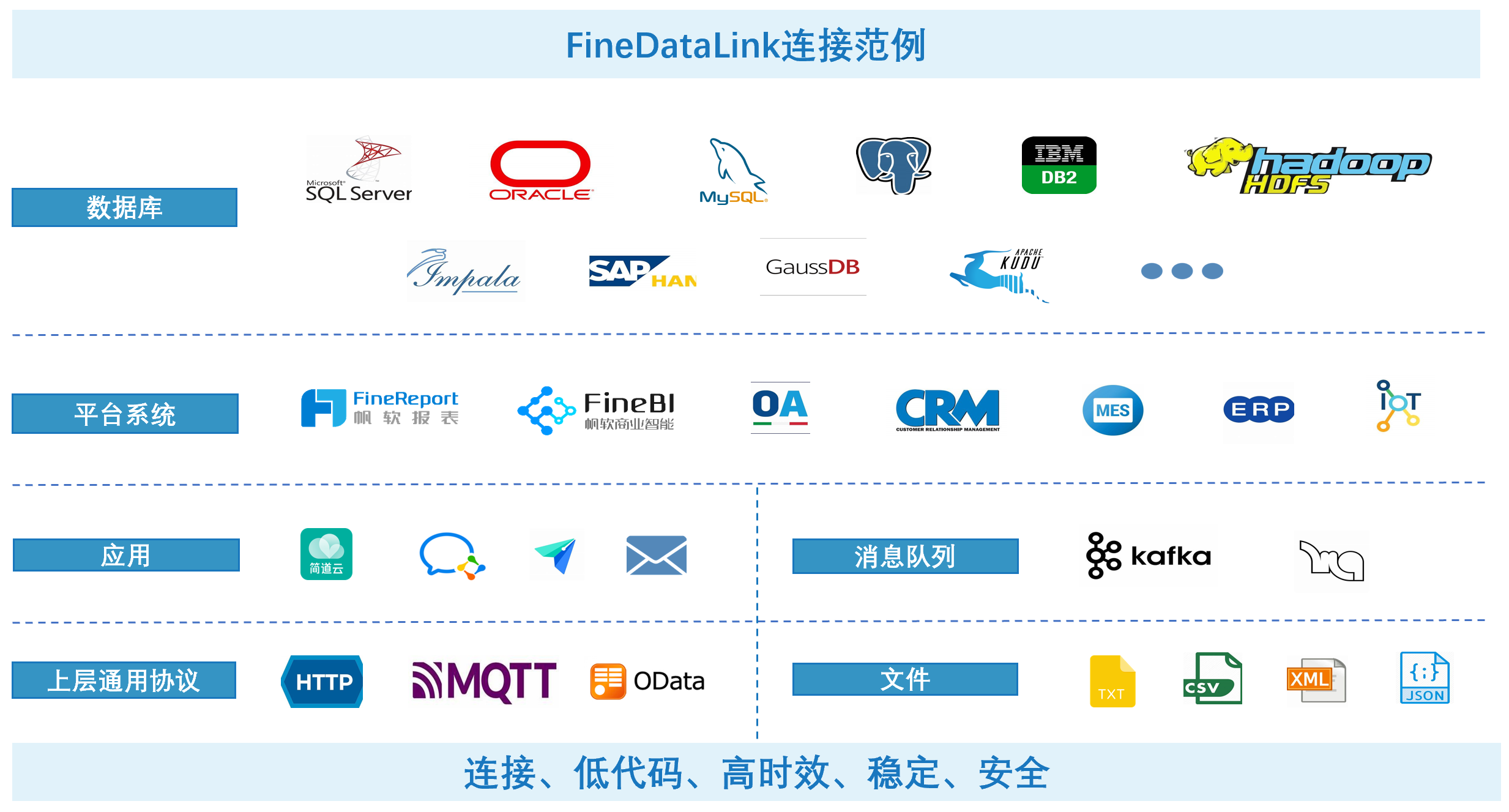
总而言之,在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 数据库与数据仓库——你想知道的都在这里下一篇: 数据仓库的本质是什么你知道吗?快进来看!

 苏公网安备32020502001567号
苏公网安备32020502001567号