作者:finedatalink
发布时间:2023.8.23
阅读次数:705 次浏览
在当今数据驱动的世界中,不同数据源之间的数据格式和结构差异成为了一个常见的问题。不同的组织、系统和应用程序使用各种不同的数据格式和结构来存储和处理数据,这意味着在数据整合和分析过程中常常需要处理这些差异。本文将介绍如何处理这些差异,以确保数据的正确性和一致性。
在处理数据格式和结构差异之前,我们首先需要对不同数据源的特点有一定理解。不同数据源可能包括关系型数据库、文本文件、API接口等,每个数据源都有其特定的数据格式和结构。了解数据源的特点能够帮助我们更好地处理数据转换过程中的差异。
根据数据源的特点和需要转换的数据格式,选择适当的转换方法是关键。常见的转换方法包括使用脚本编程或ETL工具进行转换,编写自定义的转换逻辑等。根据具体的需求和情况选择最适合的方法。
在进行数据转换时,需要定义数据映射和转换规则。数据映射是指将一个数据源的数据映射到另一个数据源的对应字段上,而转换规则是指在数据转换过程中对数据进行处理和格式化的规则。定义清晰的映射和转换规则能够确保数据的准确性和一致性。
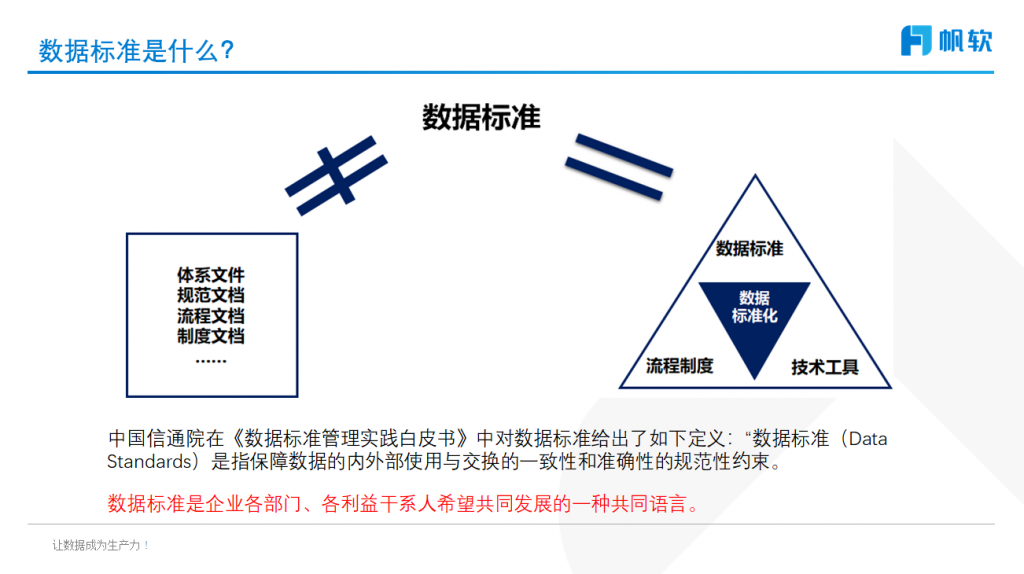
为了处理数据源之间的差异,制定统一的数据标准是非常重要的。数据标准包括字段名称、数据类型、长度、格式等方面的规定。通过制定统一的数据标准,可以减少数据转换和整合过程中的复杂性和错误。
在进行数据整合之前,需要对数据进行清洗和校验。数据清洗是指对数据进行去重、去除空值、修复数据错误等操作,以确保数据的质量。数据校验是指对数据进行验证,比如验证数据的完整性、有效性和一致性等。通过数据清洗和校验能够减少数据转换过程中的错误和问题。
ETL(Extract-Transform-Load)工具是处理数据格式和结构差异的常用工具。它可以帮助我们从不同数据源中提取数据,并进行转换和加载到目标系统中。常见的ETL工具包括Informatica、Talend、Pentaho等。使用ETL工具能够简化数据转换的过程且具有较高的可维护性和灵活性。
编写自动化脚本是另一种处理数据格式和结构差异的方法。通过编写脚本可以实现自动化的数据转换和整合过程,减少人工干预和错误。脚本编程语言如Python、Java等都可以用来编写这样的脚本。自动化脚本能够提高数据处理效率和准确性。
处理不同数据源之间的数据格式和结构差异是一个重要的任务,本文介绍了数据转换、数据标准化和自动化工具等方面的方法。通过合理选择转换方法、定义映射和转换规则、制定数据标准以及利用自动化工具,我们能够有效地处理不同数据源之间的差异,确保数据的正确性、一致性和可用性。
FineDataLink(FDL、好数连)是一款低代码/高时效的企业级一站式数据集成平台,面向用户大数据场景下,FDL实时和离线数据采集、集成、管理的诉求,提供快速连接、高时效融合各种数据、灵活进行ETL数据开发的能力,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力。
FDL是一站式的数据处理平台,拥有低代码优势。FDL通过简单的拖拽交互就能实现ETL全流程,具备高效的数据同步功能,可以实现实时数据传输、数据调度、数据治理等各类复杂组合场景的能力,提供数据汇聚、研发、治理等功能。
越来越多的业务需要更高的时效性。数据集成工具FDL提供的方案是,通过数据库日志解析等能力,FDL实现了批量表的实时同步,并且支持表结构变更同步、断点续传等,最后实现流批一体。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 实时数据同步:如何利用云计算和边缘计算提升数据处理能力?下一篇: 一文看懂!如何实现跨部门、跨地区的数据共享?


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号