作者:finedatalink
发布时间:2023.8.10
阅读次数:273 次浏览
在信息时代,数据处理已经不再是一项简单的任务,而是企业获得竞争优势的关键环节。然而,随着数据不断增长,处理数据变得更加复杂,企业需要面对异构数据的挑战、数据流的稳定性问题以及不同业务需求的多样性。本文将深入探讨数据处理领域的未来走向,着重介绍智能化、稳定性和个性化在数据处理中的关键作用,以及如何构建强大的数据处理生态系统来应对这些挑战。
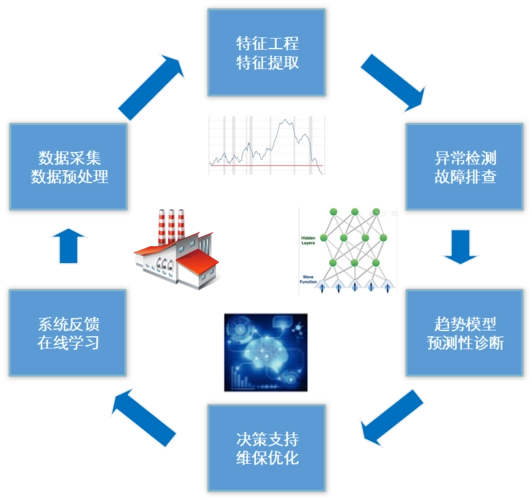
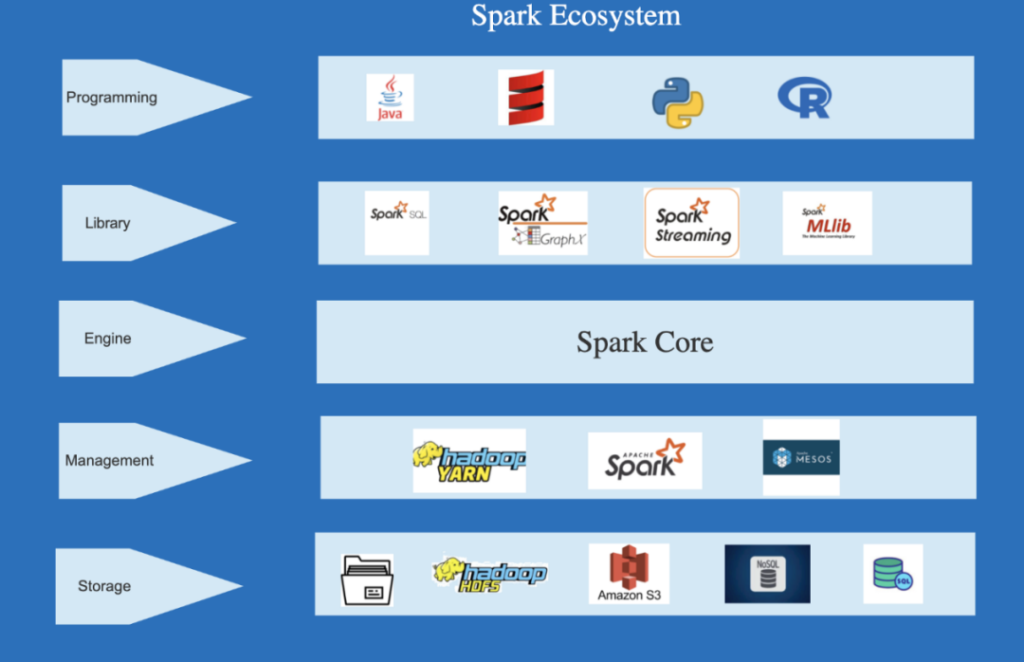
随着大数据和复杂数据处理的兴起,传统的数据处理方法已经不再能够满足需求。这时,智能计算引擎应运而生,成为数据处理的新引擎。以Spark为例,它不仅能够处理大规模数据,还可以通过内置的机器学习库实现智能化数据分析。通过内嵌智能计算引擎,企业可以更快速地处理数据,实现数据分析和决策的智能化,为业务增添更多价值。
智能计算引擎不仅仅是一个工具,它代表了数据处理的新思维,是企业在竞争中胜出的利器。通过将机器学习和数据处理相结合,智能计算引擎不仅能够高效地处理数据,还可以发现数据背后的价值,为企业提供更多商业洞察。
在数据处理中,稳定性和高可用性是至关重要的。企业需要确保数据流畅、系统不中断,从而避免数据处理中断带来的损失。为了实现这一目标,构建高可用/高并发集群架构是不可或缺的。这样的架构能够在一定程度上避免系统宕机和高负载问题,保障数据处理的连续性。
高可用性架构不仅仅是应对问题的手段,它是一种对数据处理稳定性的承诺。通过构建高可用性架构,企业能够在面对各种突发情况时保持镇定,确保数据不会中断,从而为业务提供强大的保障。
每个企业的业务需求都是独特的,因此,通用的数据处理方法往往难以满足所有需求。个性化数据处理的概念便应运而生,它允许企业根据自身需求进行定制化配置。通过合适的用户配置选项,企业可以优化数据处理流程,满足特定业务场景下的需求,从而实现更高效的数据处理。
个性化数据处理不仅仅是定制化,它是对数据的尊重和充分利用。通过理解每个企业的独特需求,个性化数据处理能够最大限度地挖掘数据的潜力,为企业提供更多创新和竞争优势。
在如今的数据处理时代,满足数据处理的未来趋势变得至关重要。通过结合智能化计算引擎、构建稳定高可用生态系统以及实现个性化数据处理,企业能够在竞争中保持领先地位。有幸的是,现在有先进的解决方案可供选择,如FineDataLink。FineDataLink为企业提供智能、稳定和个性化的数据处理解决方案,助力企业跨越数据处理的未来挑战。为了解更多关于我们的产品如何实现智能化、稳定性和个性化数据处理,请访问我们的官方网站。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 数据追踪技巧:从点击到转化的关键路径分析下一篇: 故障迁移策略优化:如何减少业务中断时间?


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号