作者:finedatalink
发布时间:2024.8.23
阅读次数:297 次浏览
在数据仓库的设计和实施过程中,选择合适的数据模型对于优化查询性能和提升数据分析效率至关重要。星型模型、雪花模型和星座模型是三种流行的数据仓库建模方法,它们各自具有独特的结构、优势和局限性。本文将深入探讨这三种模型的特点、适用场景以及如何根据业务需求进行选择。
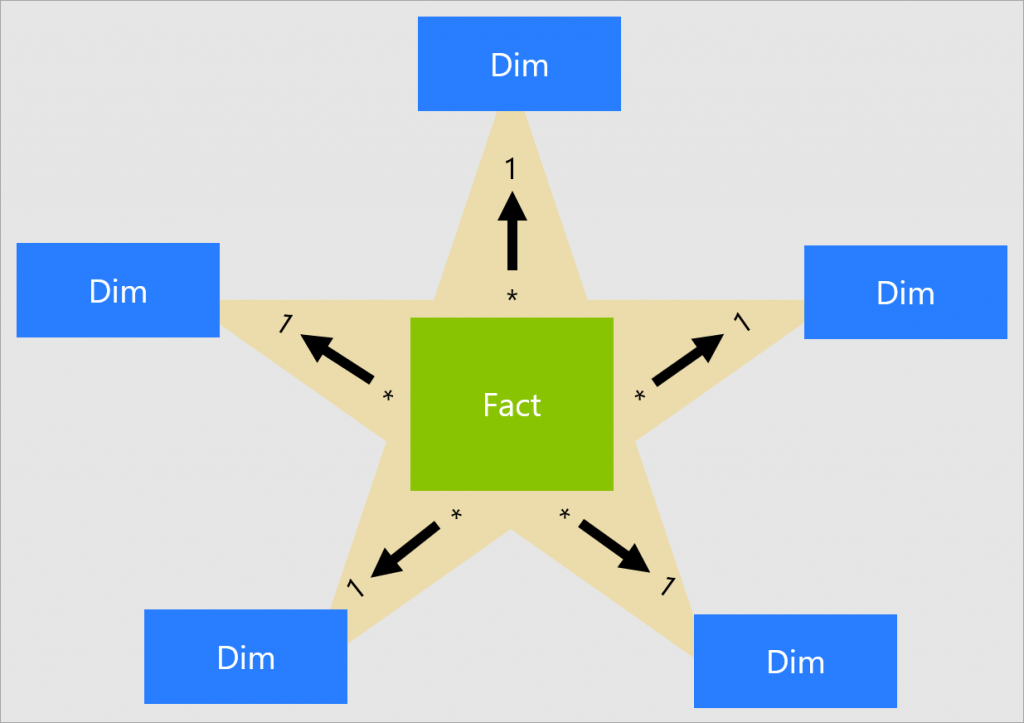
星型模型由Ralph Kimball在20世纪90年代提出,是数据仓库建模中的经典模型。其主要目的是优化查询性能,使数据分析更加高效。星型模型的设计思路源自于对多维数据模型的需求,即通过简化数据结构来支持快速的查询操作。
1.结构:星型模型由一个中心的事实表(Fact Table)和多个维度表(Dimension Tables)构成。事实表包含了可度量的数据,如销售额或利润,而维度表则包含了描述这些数据的属性,如时间、地点或产品类型。事实表与维度表之间通过外键连接,形成一个类似星形的结构。
2.优缺点:
查询性能高:由于结构简单,查询优化相对容易,能快速处理大量数据。
易于理解和设计:模型直观,业务用户和开发人员易于理解。
数据冗余:维度表的数据冗余可能导致数据不一致性。
维护难度大:随着数据量增加,维护和管理可能变得复杂。
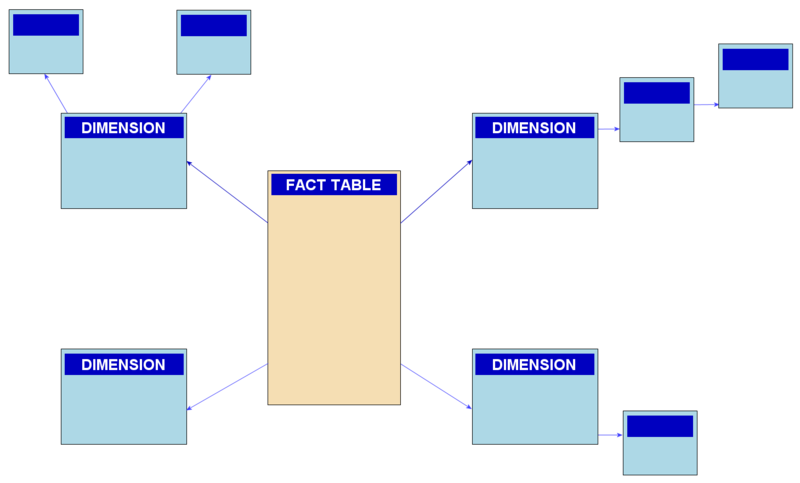
雪花模型同样由Ralph Kimball提出,是对星型模型的扩展和规范化。它的目的是通过数据规范化来减少冗余,并提升存储效率。雪花模型的名字源于其表结构的层次化外观,类似雪花的形状。
1.结构:在雪花模型中,维度表被进一步分解成多个子表,形成一个层次结构。这种规范化使得维度数据被拆分到更细粒度的表中,从而减少数据冗余。例如,产品维度表可能会被拆分成产品类别和产品子类别表。
2.优缺点:
减少数据冗余:通过规范化减少数据重复,节省存储空间。
更好的数据一致性:规范化有助于保持数据的一致性。
查询性能较差:由于表结构复杂,查询时需要进行多个连接,性能可能受影响。
设计和维护复杂:模型结构复杂,设计和维护难度较大。
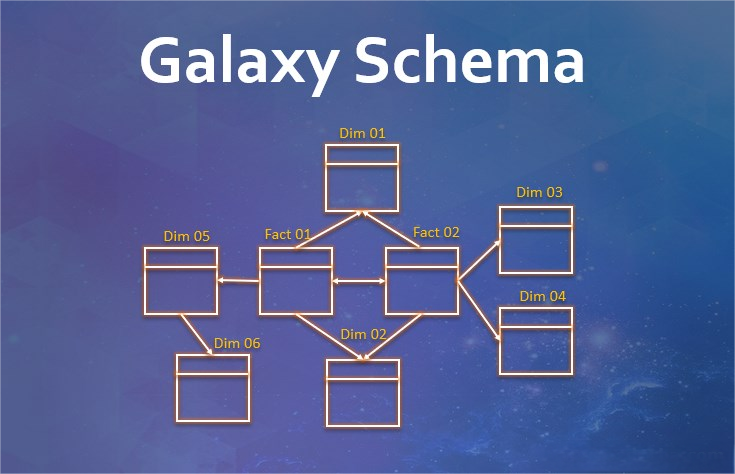
星座模型,又称为星型集合模型(Fact Constellation Schema),是对星型模型的一种扩展。它允许多个星型模型共享维度表,因此适用于需要整合多个业务领域的数据仓库。星座模型的出现满足了更复杂数据整合的需求。
1.结构:星座模型由多个星型模型组成,这些星型模型共享某些维度表。例如,一个数据仓库可能同时包含销售和库存的星型模型,这些模型共享时间和产品维度表,从而形成一个星座结构。
2.优缺点:
整合多个业务领域:适合处理复杂的业务数据,支持多角度分析。
提高维度表的复用性:通过共享维度表,减少了数据重复。
设计复杂:涉及多个星型模型,设计和维护较为复杂。
查询优化难度大:由于涉及多种业务数据,查询优化和性能调优比较复杂。
这三种模型各有其适用场景和特点,选择适合的模型取决于业务需求、数据复杂性和查询性能的要求。
通过对比星型、雪花和星座模型,我们可以清晰地看到每种模型都有其特定的优势和局限性。星型模型以其查询性能高和易于理解而受到青睐,但可能面临数据一致性和维护复杂性的挑战。雪花模型通过规范化提高了数据一致性和存储效率,但可能会牺牲一些查询性能。星座模型则为整合多个业务领域提供了强大的支持,尽管设计和查询优化的复杂度较高。最终,选择哪种模型应基于具体的业务需求、数据复杂度和性能要求,以确保数据仓库能够高效地服务于企业的决策和分析需求。
FineDataLink,它小到数据库对接、API对接、行列转换、参数设置,大到任务调度、运维监控、实时数据同步、数据服务API分享,应有尽有,功能很强大。最重要的是,因为这个工具,整个公司的数据架构都可以变得规范。而且它是java编写的,类流程图式的ETL开发模式,上手都很简单:数据对接、任务复用简直都是小case,大大降低了数据开发的门槛。在企业中被关注最多的任务运维,FineDataLink大运维平台,支持文件夹式开发模式,报错任务可一键直达修改,报错优化清晰易懂;通过权限控制,保障系统安全。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 什么是数仓拉链表?如何创建数仓拉链表?下一篇: 一文读懂:如何设计一个数据同步方案


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号