作者:finedatalink
发布时间:2024.8.14
阅读次数:204 次浏览
MapReduce编程模型的提出为大数据分析和处理开创了一条先河,之后陆续涌现出了Hadoop、Spark和Flink等大数据框架。
2004年,Hadoop的创始人受MapReduce编程模型等一系列论文的启发,对论文中提及的思想进行了编程实现。Hadoop的名字来源于创始人Doug Cutting儿子的玩具大象。由于创始人Doug Cutting当时加入了雅虎,并在此期间支持了大量Hadoop的研发工作,因此Hadoop也经常被认为是雅虎开源的一款大数据框架。时至今日,Hadoop不仅仅是整个大数据领域的先行者和领导者,更形成了一套围绕Hadoop的生态系统,Hadoop和它的生态是绝大多数企业首选的大数据解决方案。
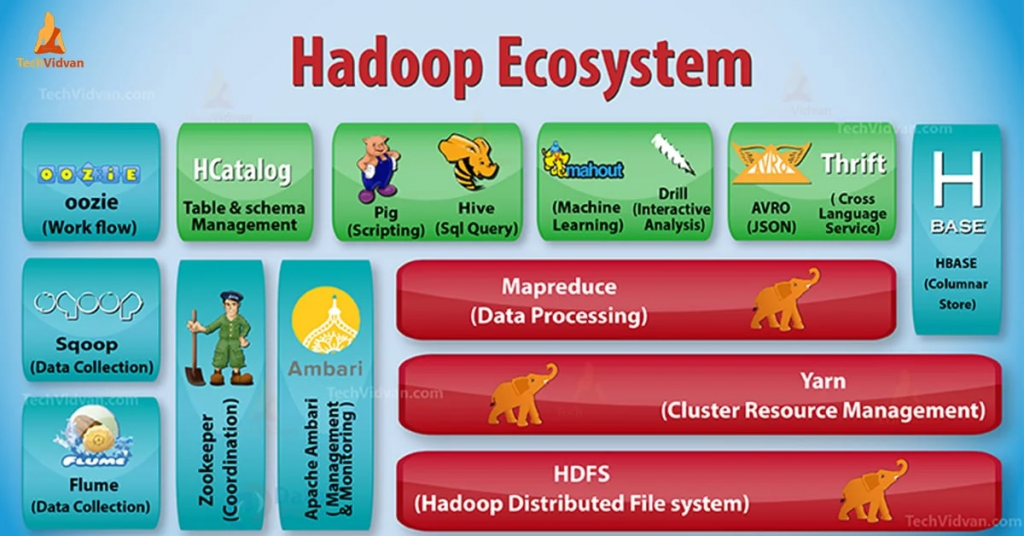
尽管Hadoop生态中的组件众多,其核心组件主要有三个:
这三大组件中,数据存储在HDFS上,由MapReduce负责计算,YARN负责集群的资源管理。除了三大核心组件,Hadoop生态圈还有很多其他著名的组件:
Spark于2009年诞生于加州大学伯克利分校,2013年被捐献给Apache基金会。Spark是一款大数据计算框架,其初衷是改良Hadoop MapReduce的编程模型和执行速度。与Hadoop相比,Spark的改进主要有两点:
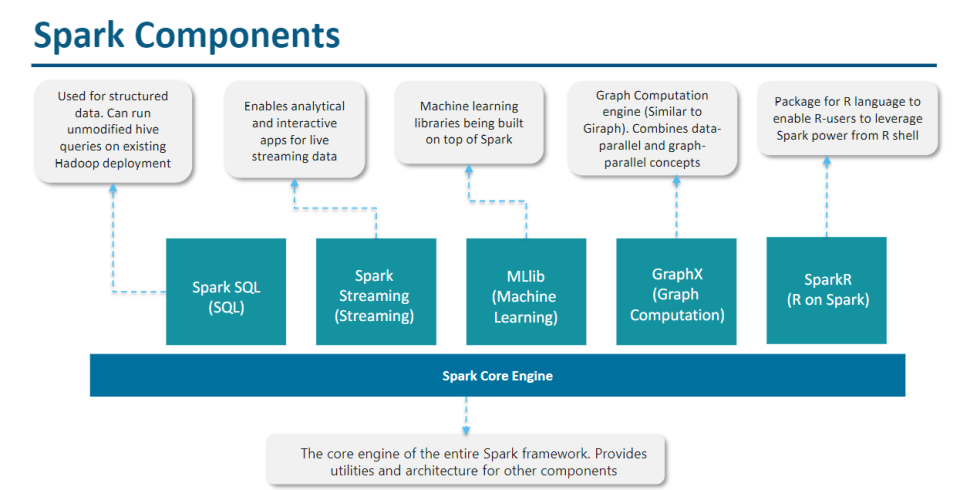
Spark生态
Spark的核心在于计算,主要目的在于优化Hadoop MapReduce计算部分,在计算层面提供更细致的服务,比如提供了常用几种数据科学语言的API,提供了SQL、机器学习和图计算支持,这些服务都是最终面向计算的。Spark并不能完全取代Hadoop,实际上,Spark融入到了Hadoop生态圈,成为其中的重要一元。一个Spark任务很可能依赖HDFS上的数据,向YARN来申请计算资源,将HBase作为输出结果的目的地。当然,Spark也可以不用依赖这些Hadoop组件,独立地完成计算。
Spark主要面向批处理需求,因其优异的性能和易用的接口,Spark已经是批处理界绝对的王者。Spark Streaming提供了流处理的功能,它的流处理主要基于mini-batch的思想,即将输入数据流拆分成多个批次,每个批次使用批处理的方式进行计算。因此,Spark是一款批量和流式于一体的计算框架。
Flink是由德国几所大学发起的的学术项目,后来不断发展壮大,并于2014年末成为Apache顶级项目。Flink主要面向流处理,如果说Spark是批处理界的王者,那么Flink就是流处理领域的冉冉升起的新星。在Flink之前,不乏流式处理引擎,比较著名的有Storm、Spark Streaming,但某些特性远不如Flink。

第一代被广泛采用的流处理框架是Strom。在多项基准测试中,Storm的数据吞吐量和延迟都远逊于Flink。Storm只支持"at least once"和"at most once",即数据流里的事件投递只能保证至少一次或至多一次,不能保证只有一次。对于很多对数据准确性要求较高的应用,Storm有一定劣势。第二代非常流行的流处理框架是Spark Streaming。Spark Streaming使用mini-batch的思想,每次处理一小批数据,一小批数据包含多个事件,以接近实时处理的效果。因为它每次计算一小批数据,因此总有一些延迟。但Spark Streaming的优势是拥有Spark这个靠山,用户从Spark迁移到Spark Streaming的成本较低,因此能给用户提供一个批量和流式于一体的计算框架。
Flink是与上述两代框架都不太一样的新一代计算框架,它是一个支持在有界和无界数据流上做有状态计算的大数据引擎。它以事件为单位,并且支持SQL、State、WaterMark等特性。它支持"exactly once",即事件投递保证只有一次,不多也不少,这样数据的准确性能得到提升。比起Storm,它的吞吐量更高,延迟更低,准确性能得到保障;比起Spark Streaming,它以事件为单位,达到真正意义上的实时计算,且所需计算资源相对更少。
之前提到,数据都是以流的形式产生的。数据可以分为有界(bounded)和无界(unbounded),批量处理其实就是一个有界的数据流,是流处理的一个特例。Flink基于这种思想,逐步发展成一个可支持流式和批量处理的大数据框架。
经过几年的发展,Flink的API已经非常完善,可以支持Java、Scala和Python,并且支持SQL。Flink的Scala版API与Spark非常相似,有Spark经验的程序员可以用一个小时的时间熟悉Flink API。
与Spark类似,Flink目前主要面向计算,并且可以与Hadoop生态高度集成。Spark和Flink各有所长,也在相互借鉴,一边竞争,一边学习,究竟最终谁能一统江湖,我们拭目以待。
FineDataLink是一款低代码/高时效的数据集成平台,它不仅提供了数据清理和数据分析的功能,还能够将清理后的数据快速应用到其他应用程序中。FineDataLink的功能非常强大,可以轻松地连接多种数据源,包括数据库、文件、云存储等,而且支持大数据量。此外,FineDataLink还支持高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等。使用FineDataLink可以显著提高团队协作效率,减少数据连接和输出的繁琐步骤,使整个数据处理流程更加高效和便捷。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 一文详解数据架构发展历程下一篇: 什么是数据仓库ODS层?为什么需要ODS层?


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号