作者:finedatalink
发布时间:2024.8.12
阅读次数:286 次浏览
随着大数据时代的到来,企业和组织对数据存储的需求呈现爆炸性增长。如何选择合适的存储方式,已经成为各类企业在信息化建设过程中亟待解决的问题。集中存储和分布式存储作为两种主要的存储架构,各自有其独特的优势和应用场景。本文将从多个维度对二者进行比较,帮助读者在不同场景下做出明智的选择。
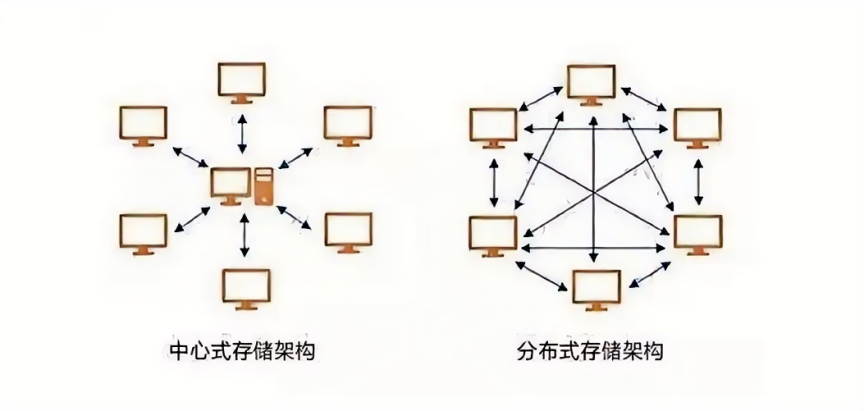
集中存储是一种传统的存储模式,通常是指将所有数据集中在一个大型存储设备或存储区域网络(SAN)中。所有的计算资源通过高速网络访问这些集中存储设备,数据的管理和维护相对集中,便于统一控制。常见的集中存储设备包括大型硬盘阵列、磁盘库和存储服务器等。
与之相对,分布式存储是一种新型的存储模式,它将数据分散存储在多个物理节点上,这些节点可以是地理上分布的多个服务器或数据中心。通过分布式文件系统或数据库,分布式存储能够将数据进行合理的切分和冗余备份,使得存储系统具备更高的扩展性和容错能力。常见的分布式存储技术包括Hadoop、Ceph、GlusterFS等。
集中存储在性能上往往依赖于高性能的硬件设备,如高速磁盘阵列和光纤通道网络。这些设备可以提供非常高的读写速度,适用于对数据访问速度要求极高的应用场景,如金融交易系统和核心数据库。集中存储在扩展性方面却存在一定的瓶颈。当数据量增长到一定规模时,升级集中存储设备的成本将大幅上升,并且还可能面临单点故障的问题,导致整个系统的可靠性下降。
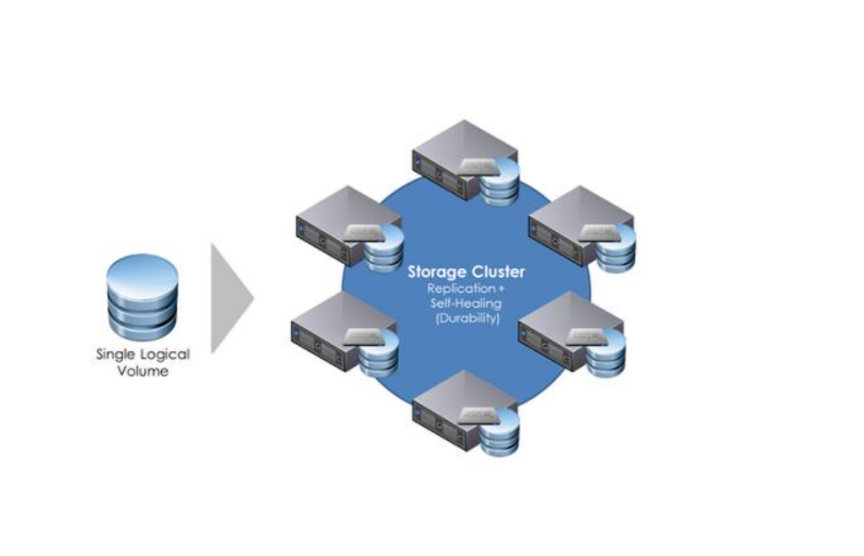
相比之下,分布式存储通过将数据分散到多个节点,可以轻松实现水平扩展。当需要更多存储空间或更高的处理能力时,只需增加新的节点即可。由于数据是分布式存储的,任何单一节点的故障都不会对整体系统产生重大影响,从而提高了系统的容错性和可用性。这种架构特别适合大规模数据处理和高可用性要求的场景,如云计算平台和互联网应用。
集中存储的管理相对集中和简单,由于数据都存放在单一或少数几个存储设备中,IT团队只需对这些设备进行统一的配置、监控和维护。这种模式使得数据的备份、恢复和安全管理变得更加高效和便捷。这也意味着,一旦存储设备出现问题,所有的数据和业务可能都会受到影响,导致整个系统的不可用。
在分布式存储环境中,由于数据分布在多个节点,管理和维护变得更加复杂。每个节点都需要独立监控,并且系统需要具备自动化的节点故障检测和恢复机制。这要求企业具备较高的技术能力和成熟的管理工具,以确保分布式存储系统的高效运行。分布式存储的数据一致性问题也需要特别关注,不同节点的数据同步和一致性检查是保障系统稳定性的关键。
集中存储由于其高性能和简单易用的特点,通常应用于对数据访问速度要求高且数据量相对可控的场景。例如,金融行业的核心交易系统、企业内部的数据仓库以及需要集中化管理的企业级应用系统等。这些应用对存储系统的可靠性、速度和统一管理有着较高的要求,集中存储是这些场景的理想选择。
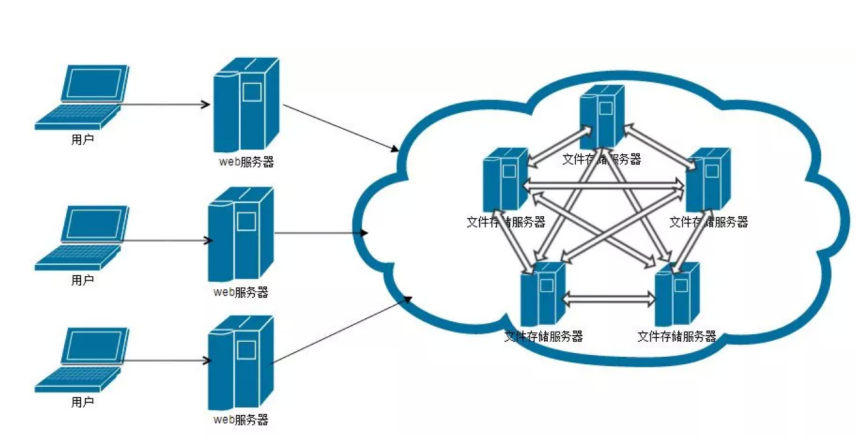
分布式存储则更多地应用于需要处理海量数据和分布式计算的场景,如云计算平台、大型互联网企业的数据中心、大数据分析平台等。在这些场景中,数据的增长速度快、分布广泛,并且需要具备高可用性和弹性扩展能力。分布式存储的架构能够有效应对这些挑战,通过多节点协作提供强大的数据处理能力和可靠性。
集中存储和分布式存储各自具备不同的优势和适用场景。集中存储适合传统的、需要高性能和集中化管理的环境,而分布式存储则更适合现代化、大规模、需要高扩展性和容错能力的场景。在实际应用中,企业应根据自身的业务需求、数据量大小、技术能力和预算等因素,选择最适合的存储解决方案。未来,随着技术的不断发展,集中存储和分布式存储可能会进一步融合,形成更加灵活和高效的存储架构,满足企业日益增长的多样化需求。
FineDataLink是一款低代码/高时效的数据集成平台,它不仅提供了数据清理和数据分析的功能,还能够将清理后的数据快速应用到其他应用程序中。FineDataLink的功能非常强大,可以轻松地连接多种数据源,包括数据库、文件、云存储等,而且支持大数据量。此外,FineDataLink还支持高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等。使用FineDataLink可以显著提高团队协作效率,减少数据连接和输出的繁琐步骤,使整个数据处理流程更加高效和便捷。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 断点续传技术解析与应用下一篇: 什么是实时数据仓库?


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号