作者:finedatalink
发布时间:2024.7.31
阅读次数:59 次浏览
Kafka在数据管道中起到了核心且关键的作用,主要作为分布式消息系统和高吞吐量的流处理平台。在现代数据架构中,数据管道通常指的是从一个或多个数据源收集数据,通过一系列的处理步骤(如转换、过滤、聚合等),最终将数据传递到目标存储或分析系统中。
本文我们就来聊聊数据管道中关键的中间件——Kafka。
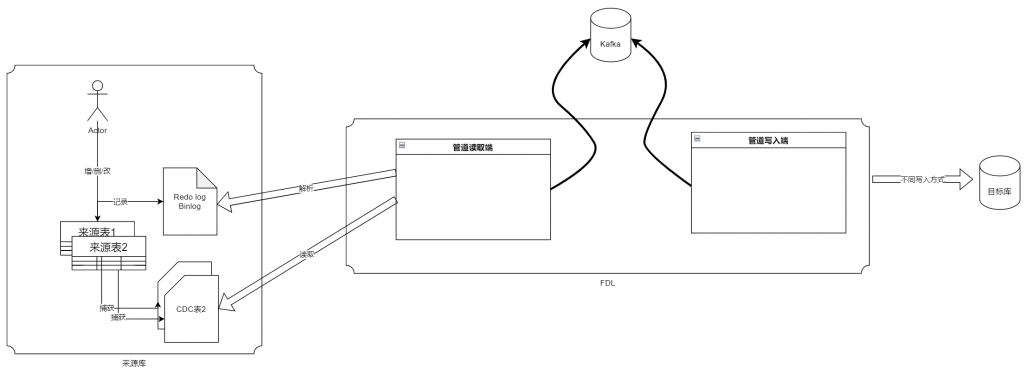
数据管道实现原理
FineDataLink监听数据管道来源端的数据库日志变化,利用 Kafka 作为数据同步中间件,暂存来源数据库的增量部分,进而实现向目标端实时写入数据的效果。
Kafka本质上是一个消息队列系统。作为数据管道的中间件,因为管道任务是实时的所以需要一个传输队列组件作为数据承载的中间站,达到可以识别断点的效果。
消息队列是一种高效的中间件技术,它作为不同应用程序或系统组件之间的通信桥梁,支持异步数据交换。它允许生产者发送消息到队列而无需等待消费者立即处理,从而提高了系统的性能和响应速度。消息队列通常提供持久化存储,确保在系统故障时消息不会丢失,并且支持消息的可靠传递和顺序保证。
Kafka是一个开源的分布式事件流平台,最初由LinkedIn开发,后成为Apache软件基金会的一部分。它以其高性能、可扩展性、容错性以及持久性而著称,能够高效地处理实时数据流。
Kafka采用发布-订阅模型,允许数据生产者发布消息到一个或多个主题,而消费者则可以订阅这些主题来接收消息。它的架构支持消息的持久化存储,确保数据不会在系统故障时丢失,并且支持消息的顺序保证和回溯读取。
Kafka的分布式特性使得它可以水平扩展,处理大量数据,适用于日志聚合、监控数据、事件源、流处理等多种场景。此外,Kafka拥有一个活跃的社区和丰富的生态系统,提供了多种客户端库、连接器和流处理工具,使其能够轻松地与现有的技术栈集成。随着大数据和实时分析需求的增长,Kafka已成为企业和技术社区中不可或缺的数据流处理工具。
介绍完了Kafka和消息队列,我们来谈谈数据管道为什么需要消息队列。
管道任务的两端数据源种类多,承载各种各样的业务,使用消息队列,可以有效将数据来源端和数据目标端解耦,达到以下效果:
性能最优:读取端和写入端可以异步读写,以各自的最佳性能运行
削峰填谷:业务高峰时,可以设置回压,对写入端的压力可以维持在一个相对恒定的水平
异常隔离:读取端和写入端异常时,互相影响程度降到最低,同时利用消息持久化的机制,保证数据安全
上面分析了管道为什么需要消息队列,而选用Kafka,则是因为它完全契合管道对消息队列的诉求。
1.Kafka实时性好,吞吐量高,便于扩展。
2.Kafka能达到解耦的效果,同时提供数据持久化机制,能有效实现削峰填谷、异常隔离的效果
3.Kafka是一个相对成熟的产品,资料丰富,社区也比较活跃,已经被很多大厂广泛使用
4.有一定的对接经验
企业在构建数仓和中间库时,由于业务数据量级较大,如果使用批量定时同步数据的方式很难做到高性能的增量同步,若使用清空目标表再写入数据的方式时,还会面临目标表一段时间不可用、抽取耗时长等问题。
因此,企业迫切希望能在数据库数据量大或表结构规范的情况下,实现高性能的实时数据同步。
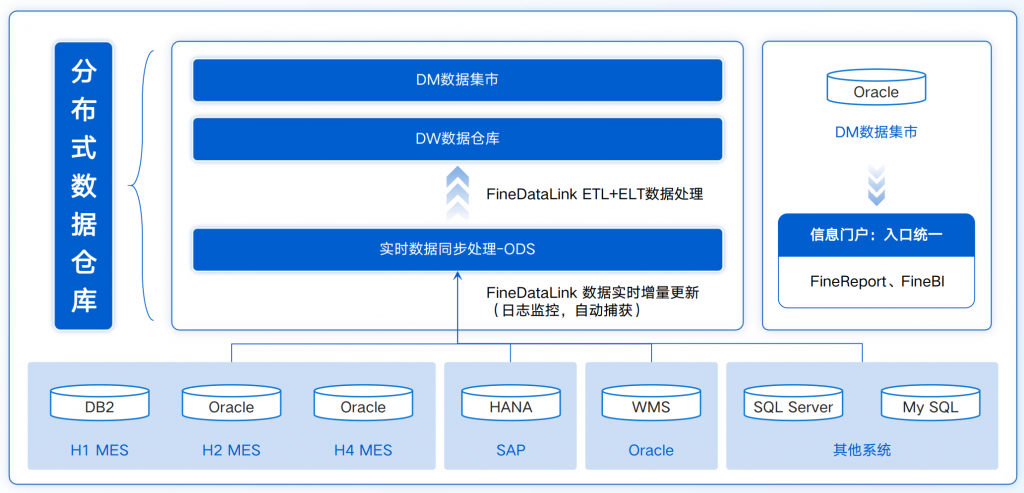
针对这一问题,FineDataLink中的数据管道功能支持对数据源进行单表、多表、整库、多对一数据的实时全量和增量同步,可以根据数据源适配情况,配置实时同步任务,解决了企业实时数据同步难题。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 数据管道的使用场景有哪些?如何实现数据管道?下一篇: 数据架构中Kafka扮演了什么样的角色?一文了解Kafka的重要性


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号