作者:finedatalink
发布时间:2023.9.1
阅读次数:323 次浏览
数据同步是在大数据环境中至关重要的一项任务,它涉及到大规模数据的传输、处理和更新。在现代数据驱动的世界中,数据同步不仅关系到企业的生产效率和数据的准确性,也是实现智能决策和优化业务流程的关键。本文将介绍如何在大数据环境中实现高效数据同步的方法和技术。
首先,为了实现高效的数据同步,我们需要选择合适的数据同步工具和技术。
在大数据环境中,常用的数据同步工具包括Sqoop、Flume和Kafka等。Sqoop是一款用于在关系型数据库和Hadoop之间传输数据的工具,它可以提供高速的并行数据传输和良好的容错性。而Flume是一种分布式、可靠的日志收集和聚合系统,可以用于将数据从多个来源传输到Hadoop平台。Kafka是一种高吞吐量的分布式消息队列系统,可以实现实时的数据同步和处理。选择合适的工具可以根据具体的业务需求和技术场景进行。
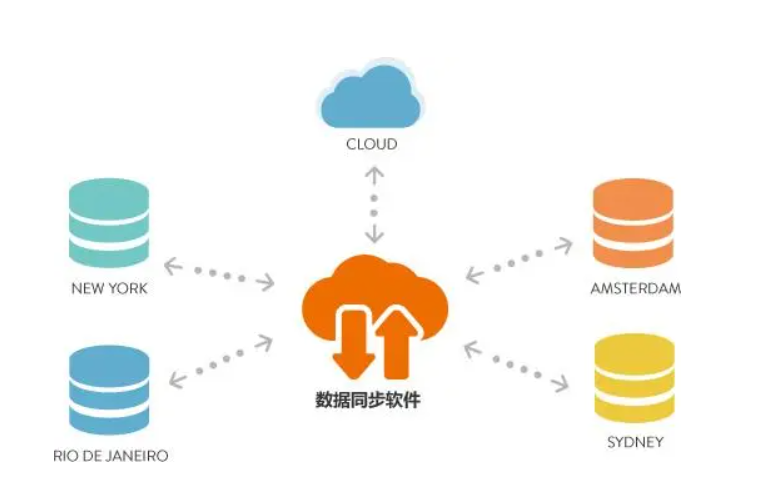
其次,为了实现高效的数据同步,我们需要优化数据传输和处理的性能。
在大数据环境中,由于数据量的巨大和复杂度的高,数据同步往往面临各种挑战,如网络延迟、数据冲突和性能瓶颈等。为了解决这些问题,可以采取以下策略:一是通过数据分片和并行化来提高传输效率,将大数据集切分成小块进行并行处理和传输;二是使用压缩和编码技术来减小数据的传输量和存储容量;三是采用缓存和预取技术来优化数据的访问和读取性能。
另外,为了实现高效的数据同步,我们还需要考虑数据一致性和容错性。
在大数据环境中,数据一致性是一个复杂而关键的问题,数据同步涉及到多个数据源和目标之间的数据一致性保证。为了确保数据的一致性,可以采取以下措施:一是使用事务和分布式锁来保证数据的原子性和一致性;二是采用日志和版本控制技术来记录数据的变更和更新;三是使用冗余和备份技术来提高数据的可靠性和容错性。
综上所述,要在大数据环境中实现高效的数据同步,我们需要选择合适的工具和技术,并优化数据传输和处理的性能,同时考虑数据一致性和容错性。通过采用这些方法和策略,可以提高数据同步的效率和准确性,实现智能决策和优化业务流程。
为了避免数据延迟和丢失,企业需要从多个方面进行努力。在这个过程中,FineDataLink产品可以帮助企业实现实时数据同步。FineDataLink具有高性能、高安全性和易用性等特点,可以有效地解决数据延迟和丢失的问题。通过使用FineDataLink,企业可以实现数据的实时同步,提高运营效率,降低经济损失。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 加速数据同步:提高效率和准确性的秘籍下一篇: 数据同步优化:提升性能与可靠性的技巧


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号