作者:finedatalink
发布时间:2023.8.24
阅读次数:481 次浏览
随着数据量的不断增长,数据仓库的查询性能一直是一个挑战。为了解决这个问题,许多组织开始探索缓存技术的应用,以提升数据仓库的查询速度。本文将介绍如何通过缓存技术来加速数据仓库的查询。
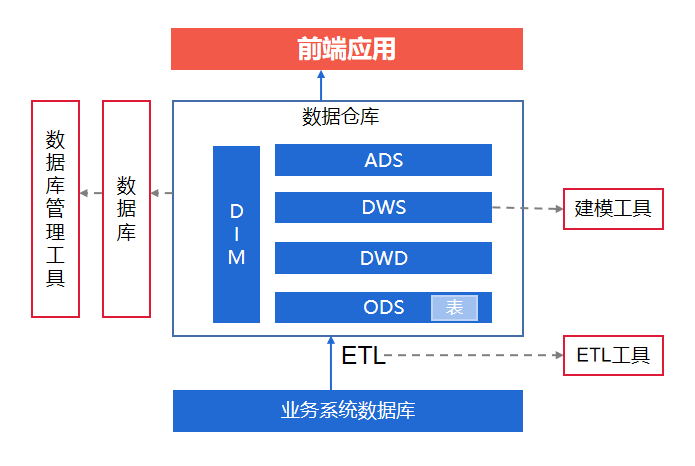
数据仓库是一个用于存储和管理大量结构化和非结构化数据的集中式数据库系统。它用于支持决策制定和业务分析,并提供快速和灵活的查询功能。由于数据仓库需要处理大量数据,并且常常需要进行复杂的联机分析处理(OLAP),因此查询性能成为一个关键的考虑因素。FDL提供了强大的数据质量控制功能,包括数据清洗、去重、格式化等,有助于提高数据质量和准确性。
加速数据仓库查询有以下几个重要原因:
1. 提升用户体验:快速的查询响应时间可以提供良好的用户体验,并增强用户对数据仓库的信任和满意度。
2. 支持实时决策:在某些场景下,实时性是至关重要的。通过加速查询速度,可以及时获得最新数据并支持实时决策制定。
3. 减少资源消耗:查询性能的提升可以减少服务器和数据库等资源的消耗,从而降低成本。
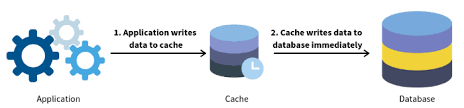
缓存技术是加速数据仓库查询的重要手段之一。它可以通过将查询结果存储在快速访问的存储介质中,减少重复的查询计算和IO操作。
常见的缓存技术类型包括:
1. 查询缓存(Query Cache):这是最简单和最常见的缓存技术之一。查询缓存将整个查询结果存储在内存中,并根据查询语句作为键进行存储。当下一次相同的查询被执行时,查询缓存会立即返回之前计算的结果,而无需再次执行查询。
2. 结果缓存(Result Cache):与查询缓存不同,结果缓存只存储查询的部分结果而不是整个结果集。这种缓存技术适用于那些查询中只有部分数据随时间变化的场景。
3. 分布式缓存(Distributed Cache):在分布式环境中,数据仓库通常由多个节点组成。分布式缓存技术将查询结果存储在多个节点的内存中,以实现高可用性和负载均衡。
选择合适的缓存策略是优化数据仓库查询的关键。以下是一些要考虑的因素:
1. 数据更新频率:如果数据的更新频率较高,查询缓存可能不太适用,因为缓存中的数据可能很快就会过期。在这种情况下,结果缓存或分布式缓存可能更适合。FDL支持实时数据采集和处理,并且可以与其他实时处理工具(如Kafka、Spark等)无缝集成,有助于企业及时了解业务状况,发现问题并及时处理。
2. 查询复用率:如果某些查询被频繁执行,查询缓存可能是一个不错的选择。查询缓存可以将这些查询的结果存储起来,并在下次执行时立即返回。
3. 缓存容量限制:缓存技术通常具有容量限制。如果数据仓库的查询结果集很大,可能需要综合考虑结果缓存和分布式缓存的组合,以满足容量需求。
为了提高缓存技术的效果,可以采取以下措施:
1. 缓存预热(Cache Warm-up):在数据仓库启动或缓存失效时,可以通过预先执行一些常见的查询来填充缓存。这样可以避免用户第一次查询时遇到缓存未命中的问题。
2. 缓存失效策略(Cache Invalidation):当底层数据发生变化时,缓存需要及时失效以保持数据的一致性。可以使用基于时间戳或事件触发的失效策略来实现缓存的自动失效。
3. 查询优化:通过对查询进行优化,可以降低查询的计算成本和IO操作。这样可以减少缓存的命中率,并提高缓存技术的效果。
通过缓存技术来提升数据仓库的查询速度是一种有效的方法。查询缓存、结果缓存和分布式缓存是常见的缓存技术类型。选择合适的缓存策略和采取优化措施可以进一步提高缓存技术的效果。通过加速数据仓库查询,可以提升用户体验、支持实时决策并减少资源消耗。
总而言之,在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink(FDL、好数连)——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据。FDL通过提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
FineDataLink(FDL、好数连)从不同数据源进行离线或实时同步,进一步进行转换、清洗等操作,向任意目标端进行写入,实现任意数据源的数据互通。
帆软推出的FineDataLink(FDL、好数连)是一款低代码/高效率的企业级数据仓库ETL工具,它可以帮助企业快速搭建数据仓库。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号