作者:finedatalink
发布时间:2023.8.16
阅读次数:241 次浏览
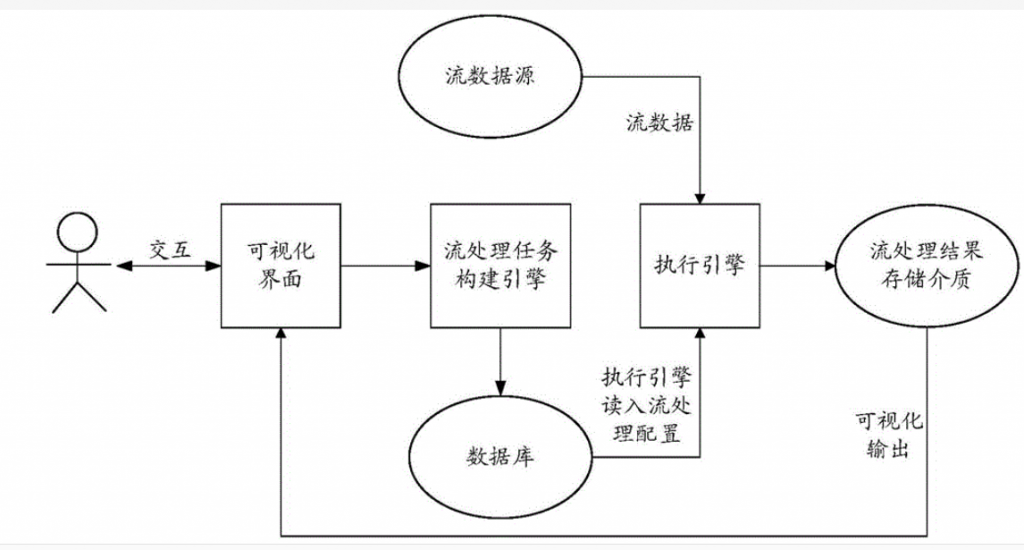
在当今数字化时代,实时数据处理已成为许多企业和组织的重要需求。从金融交易到物联网设备,实时数据的快速处理和分析对于做出及时决策和实现业务优化至关重要。为了在这些实时场景中提供卓越的数据表现,流处理能力的提升势在必行。本文将深入探讨如何优化流处理能力以改善实时场景下的数据表现。
1. 增加并行度:通过将数据流分解为独立的任务,其中每个任务由一个或多个并行处理器处理,可以显著提高流数据处理的性能。同时,使用适当的并行处理框架,如Apache Flink或Apache Spark等,可以更好地支持并行计算和分布式数据处理。
2. 缓存优化:在流数据处理管道中使用适当的缓存策略可以有效减少对底层数据库或存储系统的频繁访问,从而提高整体性能。选择合适的缓存机制和缓存策略,如LRU(最近最少使用)或LFU(最不常使用)等,可以最大限度地减少计算和处理时间。
3. 冗余消除:通过识别和消除处理管道中的冗余计算和重复计算,可以显著提高流数据处理的效率。通过使用缓存和适当的数据结构,可以减少重复计算,从而减少处理时间和资源消耗。

1. 实时性能:选择具有高度可扩展性和低延迟的流处理系统。有些系统专注于低延迟的实时数据处理,如Apache Kafka和Apache Storm等;而其他系统则更适合高吞吐量的数据处理,如Apache Flink和Apache Spark Streaming等。
2. 容错能力:对于实时场景下的数据处理,容错能力非常重要。选择具有故障恢复和容错机制的流处理系统,可以确保数据的不丢失和系统的稳定性。例如,Apache Flink和Apache Samza等系统提供了可靠性和一致性保证。
3. 易用性和灵活性:选择易于使用和灵活配置的流处理系统,以便在不同的实时场景下适应各种需求。考虑系统的API和编程模型,以及其与其他工具和技术的集成能力。
1. 压缩算法:在实时数据处理中使用合适的压缩算法可以减少数据传输和存储的开销,提高系统的整体性能。根据数据的特点和系统的要求选择适当的压缩算法,如GZip、Snappy等。
2. 数据索引:为实时数据建立适当的索引,可以加快数据的查找和访问速度,提高系统的响应性能。通过使用数据索引结构,如B树、哈希索引等,可以更快地检索和处理数据。
3. 数据分区:为了增加系统的可伸缩性和并行处理能力,将数据分区到不同的节点或分片上是非常重要的。适当的数据分区策略可以实现数据的均衡分布和更快的处理速度。
在实时场景下提高数据的表现需要优化流数据处理管道、选择适当的流处理系统和使用合适的数据结构。优化流处理能力可以提高系统的性能和实时数据处理速度,从而更好地满足实时数据处理的需求。通过合理配置并行度、优化缓存、消除冗余计算等方法,提升流处理能力,可以实现更好的实时数据表现。正确选择流处理系统,并使用适当的数据结构,可以进一步提高系统的响应性能和可伸缩性。
使用数据集成工具FineDataLink,可以转化不统一或质量低的数据,还可以将数据清洗和处理集中完成,将数据整合到数据仓库。减少数据连接和错误重试等繁琐的开发时间。完成数据清洗后,结果表会同步至数据库内,方便其他应用快速调用。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号