作者:finedatalink
发布时间:2023.8.10
阅读次数:350 次浏览
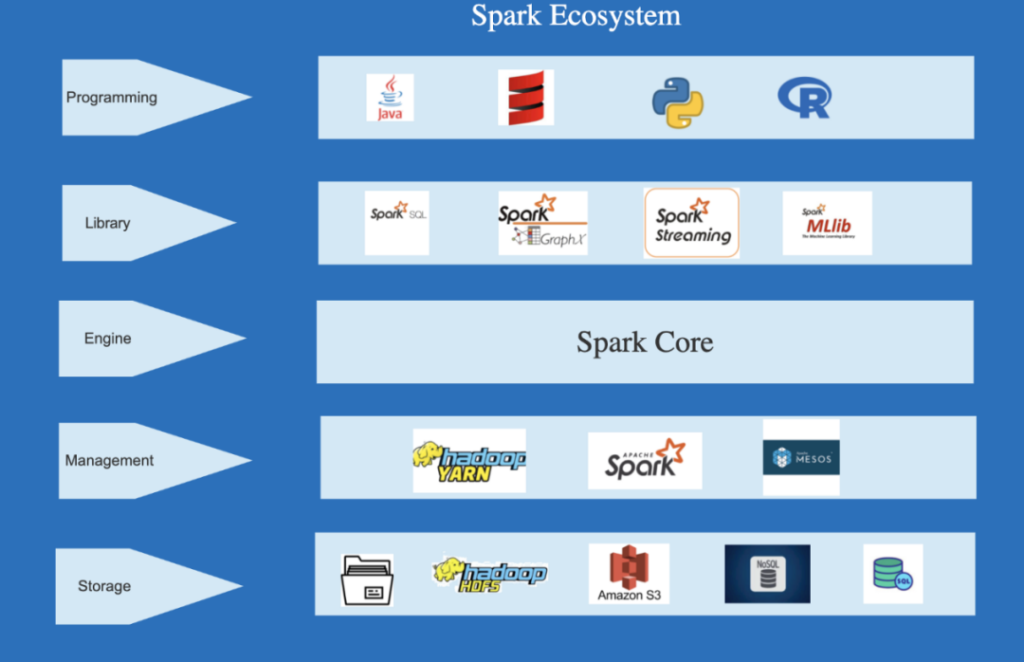 一、大数据处理
一、大数据处理在大数据处理方面,Spark计算引擎具备了高性能和可扩展性的特点。Spark使用分布式内存计算模型,可以将数据集存储在内存中进行计算,大大提高了计算速度。同时,Spark支持多种数据源的读取和写入,可以与Hadoop、Hive、HBase等各种数据存储和处理系统无缝集成。因此,Spark在大数据处理中有着广泛的应用。
举例来说,某电商公司需要对大量的用户数据进行统计和分析。他们在使用Spark计算引擎时,可以先将用户数据加载到Spark中,然后使用Spark提供的强大的数据处理功能进行数据的清洗、转换和计算。通过Spark的并行计算能力,可以高效地完成任务,并得出准确的统计结果。

Spark计算引擎还可以用于实时流处理场景。SparkStreaming模块提供了实时数据处理能力,可以将实时数据流实时地进行处理和分析。SparkStreaming可以高效地将实时数据分成批次,在每个批次内进行处理,提供了毫秒级的延迟,并保证了数据的准确性。
举例来说,某金融公司需要在交易数据中实时检测异常交易行为。他们可以使用SparkStreaming接收交易数据流,然后通过Spark提供的丰富的运算和分析功能,对交易数据进行实时的特征提取和模型计算,及时发现异常交易行为。
Spark计算引擎在机器学习领域应用广泛。Spark提供了机器学习库MLlib,包括常见的机器学习算法和工具,如分类、回归、聚类等。MLlib可以与Spark的高性能计算引擎无缝集成,实现快速的机器学习模型训练和预测。
举例来说,某保险公司需要基于客户数据构建精准的客户画像和推荐模型。他们可以使用Spark的机器学习库MLlib,利用Spark的分布式计算能力,对大量的客户数据进行特征提取和模型训练,最终得到准确的客户画像和个性化推荐结果。
Spark计算引擎在数据集成中具备了高性能和可扩展性的特点,并在大数据处理、实时流处理和机器学习等方面有着广泛的应用。通过Spark的并行计算能力和丰富的数据处理和分析功能,可以高效地处理各类数据,并获得准确的结果。随着大数据的不断增长和应用场景的不断扩展,Spark计算引擎在数据集成中的应用前景将会更加广阔。
在解决端到端异构数据问题的同时,FineDataLink追求更优的性能体验和更高的稳定性。
FineDataLink内嵌了Spark计算引擎以增强数据同步过程中的处理和计算能力,结合ETL任务的异步/并发读写机制,保证了在数据同步和数据处理场景下的高性能表现。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号