作者:finedatalink
发布时间:2023.7.26
阅读次数:374 次浏览
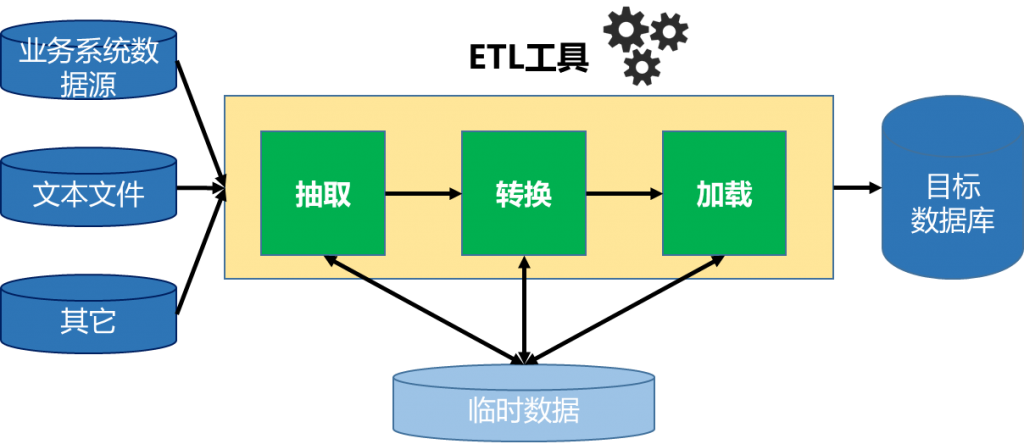
在大数据时代,ETL(Extract,Transform,Load)作业成为了数据处理的核心环节。为了提高ETL作业的性能,我们可以采取一些优化策略,同时在需要时进行水平扩展。
将大规模数据集划分为多个分区,可以减少每个作业处理的数据量,提高作业执行效率。合理选择分区字段和分区策略,可以更好地利用计算资源。
通过增加并行度,将作业划分为多个子任务同时执行,可以充分利用集群资源,加快作业处理速度。同时,合理设置并行度,避免资源竞争和数据倾斜问题。
合理安排作业的调度顺序和时间窗口,避免资源冲突和争用,保证作业的高效执行。
ETL作业中,可能需要重复读取和写入数据。采用缓存技术可以减少磁盘IO次数,提高数据读写效率。
合理分配计算和存储资源,根据作业的需求进行调整和优化,避免资源浪费和瓶颈。

将数据集切分成多个分片,分布在不同的物理节点上进行处理。通过增加节点和分片数,可以实现水平扩展,提高数据处理能力。
通过负载均衡机制,将作业均匀地分配到不同的节点上,避免单个节点负载过重,提高整体性能和稳定性。
采用分布式计算框架,如Hadoop、Spark等,可以利用集群中的多台机器进行并行计算,处理大规模的数据集。
根据作业负载的变化,自动添加或移除计算节点,实现弹性伸缩。通过动态调整资源,保证作业的高效执行,并节省资源成本。
综上所述,通过优化ETL作业性能和进行水平扩展,可以提高数据处理效率和作业执行速度。在大数据应用中,这些优化策略尤为重要,能够更好地满足业务需求,提高数据处理和分析的效果。
数据仓库ETL同步可以借助工具来完成,例如ETL工具FineDataLink。拿增量同步来举例,FineDataLink的数据管道功能通过MySQL binlog、Oracle LogMiner、和SQL Sever的CDC等日志解析,来实现数据的增量获取。同时采用流式引擎,实时捕获源数据库的变化,在毫秒内更新到目标数据库,实现数据实时同步。

数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号