作者:finedatalink
发布时间:2023.7.24
阅读次数:327 次浏览
随着信息时代的到来,各行业面临着日益增长的数据量。为了高效处理这些大规模数据,传统的计算和存储技术已经远远不能满足需求。因此,人们开始积极寻求分布式计算和存储技术的应用。
分布式计算是一种将任务分解到多个节点上进行并行计算的技术。它能够将庞大的数据集划分成小块,并分配到不同的计算节点进行处理,从而提高计算效率。在处理大规模数据时,常用的分布式计算框架包括Hadoop和Spark。
Hadoop是一个开源的分布式计算框架,它使用Hadoop分布式文件系统(HDFS)来存储数据,并提供了MapReduce编程模型来进行分布式计算。
Spark则是基于内存的分布式计算框架,具有更高的计算速度和更好的性能,并且支持多种编程语言。

与分布式计算相对应的是分布式存储技术。分布式存储是将数据分散存储在多个节点上,以提高存储容量和读写效率的技术。在处理大规模数据时,常用的分布式存储系统包括Hadoop分布式文件系统(HDFS)和分布式数据库系统。
HDFS使用数据冗余的方式存储数据,保证了数据的高可靠性。同时,它支持数据的分布式读写操作,以提高读写速度。
分布式数据库系统则将数据分布在多个节点上进行存储和管理,以提高查询和事务处理的效率。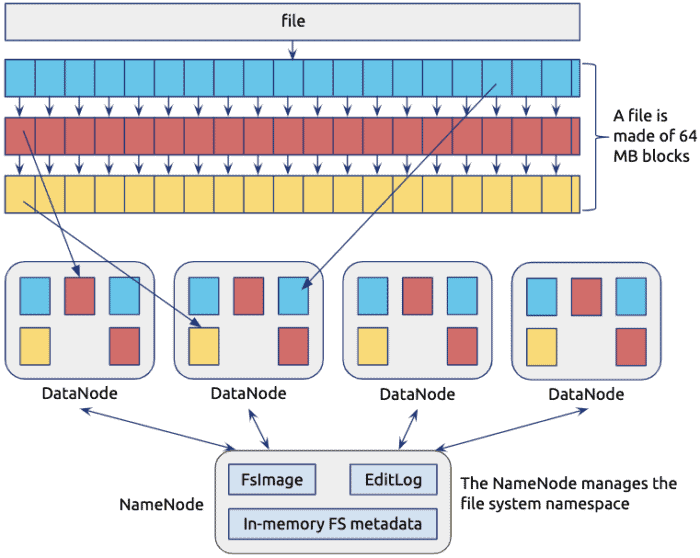
在现代企业中,大规模数据处理的分布式计算和存储技术发挥着重要的作用。接下来以推广运营为例来说明。
1、 分布式计算技术提供高效的计算能力,帮助企业快速处理和分析大量的数据,从而得到更准确的营销策略和预测结果。
2、 分布式存储技术提供高容量和高可靠性的存储能力,确保数据的安全和可靠性。
3、 分布式计算和存储技术的并行处理能力可以大大缩短推广的时间,提高效率。
分布式计算和存储技术是处理大规模数据的有效工具。无论是在科研领域还是业领域,它们都发挥着重要的作用,能够帮助企业高效处理和分析大量的数据。因此,对于需要处理大规模数据的企业来说,掌握和应用分布式计算和存储技术至关重要。作为低代码/高时效的ETL数据集成平台,FineDataLink面向用户大数据场景下,如果您需要在ETL技术中获得更高效的数据处理能力,FineDataLink将是您的理想选择。
数据集成平台产品更多介绍:www.finedatalink.com


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号