作者:finedatalink
发布时间:2023.9.26
阅读次数:987 次浏览
一般来说数据同步有两种方式:数据全量同步、数据增量同步
①数据全量同步:数据是先删后插入,但这样会造成数据短时间范围内的空缺,所以这样的方式在大数据量的情况下不是很可取
②数据增量同步:是通过主键对比的方式进行数据更新,这样就不存在数据空窗期的问题了
所以数据增量同步会更匹配题主目前的需求。
那可能有人会问,字段主键对比,假如是用SQL的方式怎么进行对比啊,数据量这么大....
那这时候就推荐通过时间戳的方式来进行增量对比更新,把上一次更新完的时间点保留下来,下一次通过这个字段的过滤,来进行数据同步。
且假如是用日志增量的实时同步技术,例如mysql的Binlog、Oracle的Logminer、sql Server的CDC等等,就不用担心要保存时间戳或者其他的配,因为一旦当数据库表字段有任何变化,在日志中都会被记录下来,直接对这部分的数据进行增、删、改即可!
假如是数据实效性不高,就可定时的方式来进行数据同步,那这时候数据源的获取可以通过SQL的方式,常用工具有开源的kettle等
但假如是对数据实效性有要求,需要实时数据同步,那基本方法是直接通过SQL Server的日志CDC模式进行实时同步,这样源库的变化,就能时刻同步到目标库,常用的工具有FineDataLink数据集成平台等
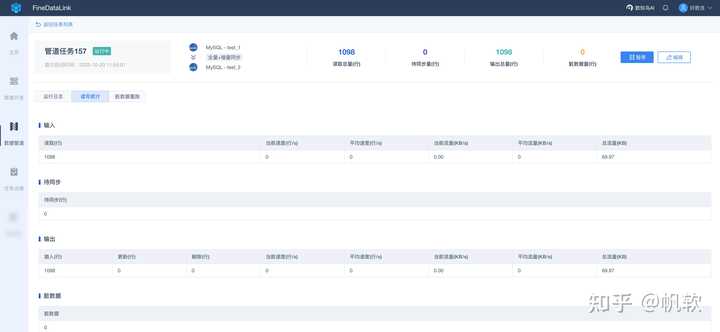
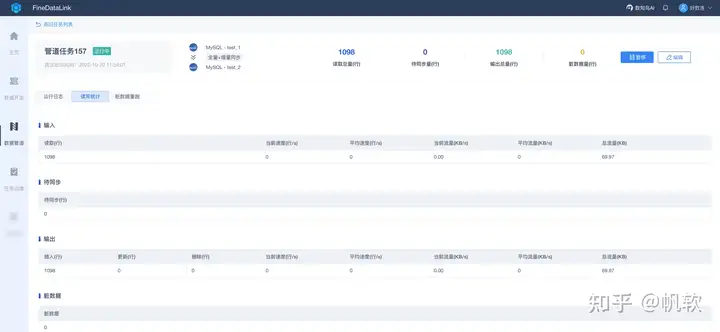
在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 数据同步工具怎么选?好用的数据同步工具推荐下一篇: 一站式数据集成平台


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号