作者:finedatalink
发布时间:2023.7.28
阅读次数:358 次浏览
有软件可以实现,但要想实现异构数据库的统一访问,例如select http://oracle.XXX from XXX ;where oralce.XXX.id=sqlserver.XXX.id,首先要先明白这类数据计算运行的底层逻辑是什么。
①假如是通过异构数据库,直接进行左右关联,那这类数据的计算就是在运行软件/程序的服务器。
②假如只是数据的一个统一访问,然后进行OLAP关联分析,用BI工具就行。
③假如是除了数据的统一访问,还需要进行数据的再次处理,那还是推荐通过数据集成工具,将分布在不同网络、不同服务器上的不同种的数据库中的数据,集成到一个数据库,再进行处理,这样的话,就是统一将算力放到这个新的目标数据库中,同时也不会影响原有数据库的使用,也就是搭建数据仓库的最常见做法。
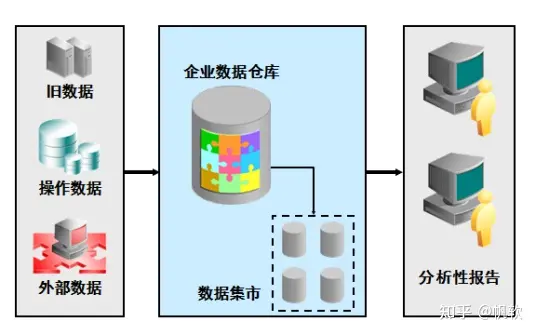
但其实很多人,看到搭建数据仓库会比较排斥,觉得这是大公司级别才会做的事情,其实不然,你可以根据你的数据库或者系统数据的体量,进行一定程度裁剪,搭建数据仓库使之符合自己数据使用习惯就行。现在这类市面上有很多数据集成工具,可以做到这点,开源的有kettle,商业的有FineDataLink,通过设置流程,很快就能完成异构数据库的数据迁移集成。
可以。但最好是在异构数据库很多,数据量很大时,再去选择分布式数据库,这样数据的存储能力和算力都会进一步提升。假如数据量单机数据库就能支撑,其实就没必要采用分布式数据库。为什么呢?因为一般来说,分布式数据库都是由主节点+N个计算存储节点,具备可扩展、高可用(当部分节点失效时,其他节点能够接替它继续服务)的能力,因此一般购买成本、运维成本都比较高。所以,如果数据量单机数据库就能支撑,采用分布式数据库就比较“浪费”,性价比不如使用上面提到的数据集成工具高。
在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。

数据集成平台产品更多介绍:www.finedatalink.com
上一篇: 做数据库设计的6个注意事项下一篇: 数据库实用知识点:5种数据迁移常用方法分享


 帮助文档
帮助文档 学习视频
学习视频

 苏公网安备32020502001567号
苏公网安备32020502001567号